| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
  07/09/2012 16:14 07/09/2012 16:14 | |
Tutorial voxforge, tradotto e senza errori Grazie a questo tutorial, chiunque può crearsi i propri modelli acustici e utilizzare Julius sul proprio computer (con sistema operativo Windows), per riconoscere la propria voce.
Tutorial originale per Windows: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/...
Tutorial supportato da Calel:
DOWNLOAD
(Task originale su www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/... )
Tutti i software che servono per il nostro scopo sono stati scritti per girare su sistemi operati Unix, per cui, la prima cosa da fare è scaricare e installare un ambiente di simulazione Unix.
Posso immaginare che un utente poco esperto di programmazione, potrebbe già sentirsi perso nei primi 3 righi che ha letto.
Non c'è problema se non sai di cosa stiamo parlando, basta fare quel che sta scritto e tutto funziona.
Serve sapere solo 1 cosa: il tuo sistema operativo è Windows?
No, allora smetti di leggere non è questo il tutorial giusto per te.
Si, bene, continua, tutto funzionerà.
1) Scaricare la Cygwin.
La Cygwin è un componente necessario per poter utilizzare Julius e per poter costruire i nostri modelli acustici.
In particolar modo, la Cygwin, è la piattaforma sulla quale faremo funzionare tutto. Se vuoi avere una visione qualitativa di cos'è la Cygwin, dai uno sguardo a www.patital.com/26061/che-cosa-cygwin
Per scaricare la Cygwin, apri un'altra scheda di navigazione dal tuo browser e connettiti all'indirizzo: www.cygwin.com/
Appena accedi alla pagina della Cygwin, troverai in alto, una scritta "Cygwin" rossa (piuttosto grande), sotto a questa, leggi la scritta sempre rossa "Current Cygwin DLL version".
Sei a cavallo.. Sotto quest'ultima scritta leggerai:
"The most recent version of the Cygwin DLL is 1.7.16-1. Install it by running setup.exe."
Clicca su "setup.exe".
Quando il download è finito (ci mette pochi secondi), clicca sul file appena scaricato. Ti si aprirà una finestra di scelta dove trovi il pulsante "Install Cygwin now" (o qualcosa di simile), cliccaci su.
2) Installare la Cygwin.
Dopo aver avviato l'istallazione (doppio click sul file setup.exe), si aprirà il programma d'istallazione della Cygwin, questo ti presenterà una serie di schermate dove ti verranno chieste opzioni particolari d'istallazione..
Queste opzioni sono tutte descritte in quel che segue, ma l'ordine di presentazione di queste "scelte", potrebbe essere diverso (di sicuro lo sarà), tra questa discussione e l'installazione che ti si presenterà sullo schermo.
Non preoccuparti, calma e sangue freddo!
Prima di tutto, ti basterà continuare a leggere per trovare qui sopra quel che ti serve, poi, se hai problemi, puoi sempre iscriverti al forum e chiedermi aiuto!
---- Schermata di richiesta sorgente di download..
(Choose a download source)
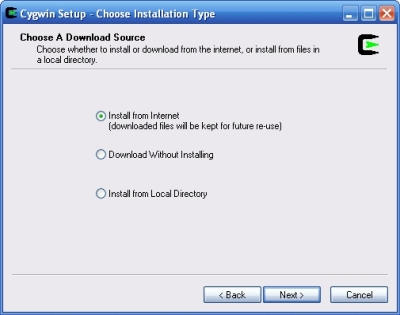
Seleziona "install from internet".
---- Schermata di scelta del tipo di connessione..
(Select your internet connection)
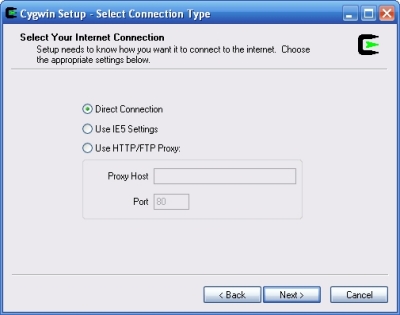
Seleziona "direct connection".
---- Schermata di selezione pacchetto..
(Select local package directory)
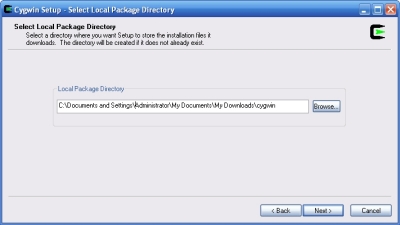
Non muovere niente, vai avanti!
---- Schermata di scelta della root..
(Select root install directory)
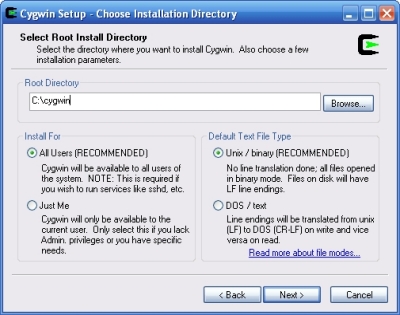
Installa la tua root directory su "C:\cygwin" (attento a come scrivi: non lasciare spazi tra le parole, rispetta le lettere minuscole e le lettere maiuscole, altrimenti dopo avrai difficoltà..);
Seleziona "install for all users" e "Unix/binary".
---- Schermata di scelta del server da cui scaricare..
(Choose a download site)
Scegline uno a caso ;-)
---- Schermata di selezione pacchetti
(Select packages)
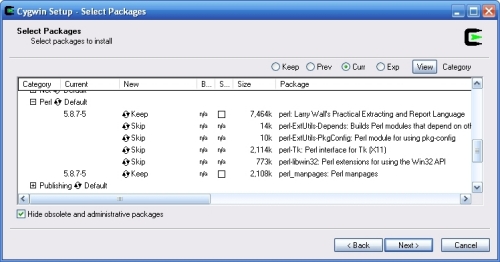
Qui ci vuole un pò di attenzione, si devono scegliere delle voci particolari all'interno della selezione che si vede...
1-Clicca per selezionare "Perl", si aprirà una sotto-scelta;
2-Clicca per selezionare "perl: Larry Wall's Practical Extracting and Report Language";
3-Clicca per selezionare "perl_manpages: Perl manpages";
4-Torna sulla lista di selezioni che vedi alla tua sinistra, trova la voce "Devel" e cliccala per selezionarla, si aprirà una nuova sotto-selezione;
5-Clicca e seleziona, da quest'ultima sotto-selezione, la voce "gcc-core - C compiler";
6-Clicca e seleziona "make - GNU version of make utility";
7-Clicca e seleziona "flex - fast lexical analyzer generator";
8-Torna alla prima scelta di selezione (le voci che vedi alla tua sinistra) e clicca per selezionare "Utils", si apre una nuova sotto-selezione;
9-Da questa nuova sotto-selezione clicca per selezionare "diffutils - A GNU collection of diff utilities";
10-Torna alla prima scelta di selezione (le voci che vedi alla tua sinistra) e clicca per selezionare "Libs", si apre una nuova sotto-selezione;
11-Dalla lista di scelte che si apre, seleziona "zlib - the zlib compression and decompression library".
Fai attenzione, alcuni nomi selezionabili sono simili, ma tu dei spuntare quello che hai il nome uguale rispetto a quello che io ho scritto tra virgolette.
Dopo aver selezionato tutto, vai avanti nell'installazione e aspetta qualche minuto che il programma scarichi tutto quello che ti serve.
3) CONTROLLO DELL'INSTALLAZIONE DELLA CYGWIN.
Premi START, vai in "programmi", scegli "cygwin", scegli "Cygwin Bash Shell".
Si apre una finestra con sfondo nero.. Aspetta qualche secondo che la cygwin sia pronta, dopo di che scrivi (rispettando le lettere minuscole e maiuscole come gli spazi):
"perl -v"
Nota bene: sulla cygwin non devi scrivere le doppie virgolette, ma solo perl in minuscolo, seguito da un carattere di spazio, poi digita il trattino e subito dopo, la lettera minuscola v.
Premi invio e leggerai una sequenza di righe che significano che fin ora te la sei cavata alla grande!!!
...Continua con il Download e l'installazione dell'Hidden Markov Model Tool Kit (HTK per gli amici)... |
| |
|
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 09/09/2012 14:41 | |
L'hidden Markov model toolkit è un insieme di librerie scritte in perl e C, che servono per la creazione, la gestione e l'elaborazione di modelli nascosti di Markov. I modelli nascosti di Markov, sono un potente modo di elaborazione statistica di processi il cui stato -di per se- non è misurabile.
In effetti il vostro computer quando si trova ad ascoltare la vostra voce dal microfono, non sa quello che voi potreste dire! Quindi potete immaginare che i calcoli che un riconoscitore vocale deve effettuare sono anche molto legati a condizioni statistiche..
Quanto dovete sapere di statistica? Niente. Non dovete essere voi a stillare statistiche ma utilizzerete questo simpatico tool!
Quanto dovete sapere di modelli nascosti di Markov? Niente. Utilizzando questo tutorial, vi verrà semplicemente chiesto di scrivere dei comandi sulla Cygwin e di creare dei file con all'interno delle parole chiave.
Il tutorial originale per questa parte di preparazione dell'ambiente di sviluppo, lo trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/...
Procediamo con il lavoro!
3) Scarica HTK.
Per scaricare l'HTK, è necessaria un'iscrizione al sito di sviluppo. Capisco che può ai più può sembrare una perdita di tempo, ma se non si vuole cacciare soldi, un minimo di tempo si deve "investire"!
Aprite in un'altra scheda questa pagina: htk.eng.cam.ac.uk/register.shtml
Compilate tutti i campi, immettendo -almeno- la vostra mail in maniera esatta.. Dopo aver compilato i pochi campi, scorrete la pagina verso il basso e premete il pulsante "yes".
Vi verrà inviata una mail all'indirizzo che avete specificato, all'interno di questa troverete una password.
Questa password, insieme al nome utente scelto da voi, vi serviranno per accedere al sito dell'HTK.
Non vi resta che scaricare il tool, seguendo questa procedura:
1- clicca sull'indirizzo:
htk.eng.cam.ac.uk/ftp/software/htk-3.3-windows-binary.zip
2- Si dovrebbe aprire una finestra che chiede username e password, scrivete la username che avete scelto e la password che vi è stata inviata tramite e-mail, quindi chiudete la scheda e cliccate nuovamente sullo stesso indirizzo: htk.eng.cam.ac.uk/ftp/software/htk-3.3-windows-binary.zip
Il download verrà effettuato in automatico.
3- Clicca sull'indirizzo: htk.eng.cam.ac.uk/ftp/software/HTK-samples-3.3.zip
Il download verrà effettuato automaticamente.
4) Installa HTK.
Apri le risorse del computer, clicca una volta sul disco fisso C: (anche se si ha più di un disco fisso, se si sono seguite queste istruzioni, trovate sempre tutto come viene descritto).
Apri la cartella Cygwin.
Crea una nuova cartella all'interno della cartella Cygwin (già ti trovi dentro la cartella cygwin, quindi non ti resta che cliccare con il pulsante destro del mouse su un punto qualsiasi della finestra che vedi, ma non su altre icone, clicca nello spazio bianco, ti si apre un menù, da questo seleziona "nuova cartella").
Chiama la nuova cartella "HTK" e lasciala aperta.
Copia i due file che hai appena scaricato.. In genere i file che vengono scaricati da internet vengono memorizzati (quindi li trovi lì), all'interno della cartella documenti, in una cartella che si chiama "Download" o qualcosa di simile ("Downloads"..).
I file che hai appena scaricati si chiamano:
"htk-3.3-windows-binary.zip" e "HTK-samples-3.3.zip".
Bene.. Copia questi due file e incollali nella cartella HTK, che hai precedentemente creato all'interno della cartella cygwin.
(per copiare un file, non devi fare altro che cliccare sopra al file con il pulsante destro del mouse e selezionare la voce "copia". Per incollare un file che si è precedentemente copiato, basta cliccare in un punto qualsiasi della cartella destinazione, con il pulsante destro del mouse e selezionare la voce "incolla")
Dopo aver copiato i due file nella cartella HTK, fate un click con il pulsante destro del mouse sopra al file "htk-3.3-windows-binary.zip" e dal menù che vedete, selezionate "Extract All" (potresti non leggere questa opzione ma opzioni tipo "Extract Here", "Estrai qui", "Estrai in htk-3.3-windows-binary", vanno bene allo stesso modo!).
Questo procedimento si deve ripetere per il file "HTK-samples-3.3.zip".
5) Copia alcuni script HTK.
La prima cosa da fare è capire come si chiama la tua "directory di lavoro".. Questa deriva dal nome che è stato dato al computer e/o dal nome di un eventuale account, comunque è importante che venga capito il nome specifico in maniera corretta, per farlo utilizziamo la cygwin.
Vai su start, programmi, cygwin e seleziona cygwin bash shell.
All'interno della finestra con sfondo nero che ti si apre, scrivi il seguente comando: "pwd" (scrivilo tutto minuscolo e senza le doppie virgolette). Premi quindi il pulsante "invio" che trovi sulla tastiera.
La cygwin, a questo comando, risponderà scrivendoti la tua directory di lavoro (la cygwin sa come si chiama il tuo computer e non commette errori). In genere viene scritto un qualcosa del genere:
/home/Administrator
Ma al posto di "Administrator", potresti trovare scritto il tuo nome tipo:
/home/Carlo
Oppure /home/Windows.
Ad ogni modo ora sai che la tua directory di lavoro è /home/[nome], dove [nome], può essere Administrator, Carlo, il tuo nome oppure Windows..
Proseguiamo..
Vai in risorse del computer, clicca sul disco fisso C:, apri la cartella "cygwin", apri la cartella "home".
Ti ricordi quel che hai letto dalla cygwin? /home/[nome]
Bene, apri la cartella che si chiama [home].
(se non hai mai installato la cygwin o meglio.. Se non è mai stata installata la cygwin sul tuo computer, dovresti trovare all'interno della cartella "home", solo un'altra cartella, quindi non dovresti avere incertezze!)
All'interno della cartella [nome], crea una nuova cartella e chiamala "voxforge".
Dopo averla creata, apri la cartella "voxforge" e crea una nuova cartella chiamandola "HTK_Scripts".
Lascia aperta questa cartella e vai su risorse del computer, clicca C:, poi cygwin, poi HTK, poi htk-samples-3.3, poi samples, poi RMHTK, poi perl_scripts.
Troverai un elenco di file, tra questi copia il file "mkclscript.prl", chiudi la finestra e incollalo nella cartella che hai creato prima e chiamato HTK_Scripts.
Apri risorse del computer, vai su C:, vai su cygwin, vai su HTK, vai su htk-samples-3.3, vai su samples, vai su HTKTutorial.
Trovi anche qui un elenco di file, copia "maketrihed" e incollalo sulla cartella che hai chiamato HTK_Scripts, copia "prompts2mlf" e incollalo nella stessa cartella, copia "prompts2wlist", chiudi la finestra e incollalo nella stessa cartella (HTK_Scripts).
6) Modifica mkclscript.prl per farlo funzionare sulla cygwin.
Vai in risorse del computer, poi in C:, poi in cygwin, poi in home, poi in [nome], poi in voxforge, poi in HTK_Scripts.
Clicca con il pulsante destro del mouse sopra il file che si chiama "mkclscript.prl", ti si aprirà un menù dal quale devi selezionare "apri con", dall'elenco di programmi, scegli "notepad" (oppure WordPad).
Ti si apre un editor di testo con dentro scritto il codice sorgente di mkclscript.prl, devi solo vedere dove sta scritta la parola "chop;".
Ogni volta che trovi la parola "chop;", posiziona il cursore del mouse dopo il punto e virgola e scrivi nuovamente "chop;".
Nient'altro.. Devi solo sostituire la parola "chop;" con "chop;chop;".
Non modificare nient'altro!
Salva il le modifiche che hai apportato..
Apri la cygwin:
1- scrivi "cd [nome]" ([nome] è il nome della tua directory di lavoro, quella che hai letto nel passo precedente!) e premi invio;
2- scrivi "cd voxforge" e premi invio;
3- scrivi "cd HTK_Scripts" e premi invio;
4- scrivi "dos2unix mkclscript.prl" e premi invio;
Finito. Hai installato le librerie HTK che ti servono.
![[SM=g27989]](https://im0.freeforumzone.it/up/0/89/12259182.gif)
.. Continua con l'installazione dell'engine di speech to text Julius. [Modificato da calel82 09/09/2012 18:33] |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 10/09/2012 12:17 | |
Julius è un software gratis che ti permetterà di effettuare il riconoscimento vocale sul tuo computer.
Il tutorial originale proposto da voxforge, propone la messa in opara di Julian e non di Julius, ma i dati preparati possono essere utilizzati per rendere operativo anche lo stesso Julius.
Nel pacchetto d'installazione di Julius, ci sono tantissimi tool e terzi software che possono essere utilizzati per diverse esigenze legate al riconoscimento vocale.. Uno di questi "sotto sistemi" di Julius è Julian. Julian permette all'utente di utilizzare comandi vocali per guidare il computer. Nel tutorial proposto da voxforge, si "fa finta" di costruire tutto quello che serve per utilizzare Julian per effettuare telefonate dal proprio computer. Ciò non è possibile con le sole operazioni descritte sul tutorial voxforge! Manca infatti tutta una serie di operazioni e passaggi che mettono in grado -prima di tutto- il computer di effettuare telefonate e Julian di richiamare queste funzioni. Lo scopo del tutorial voxforge è solo quello di spiegare e illustrare come creare quello che serve a Julian per effettuare il riconoscimento vocale, non altro. Tuttavia Julian è solo una sotto-funzione di Julius, è infatti Julius il sistema completo di riconoscimento vocale. Pur riconducendomi per lo più al tutorial voxforge, in questo tutorial che vi propongo, si utilizzerà Julius e non Julian, inoltre verranno proposti tutti i passi in maniera chiara e funzionale, svelando anche "retroscena" funzionali non descritti su voxforge e che possono creare confusione e generare errori di costruzione del modello acustico, il cui risultato è la perdita di fiducia nelle proprie capacità da parte del lettore.
Detto questo, cominciamo a tirar su il nostro riconoscitore vocale, completo e funzionale..
7) Scaricamento e installazione di Julius per Windows.
La versione che il tutorial voxforge propone è una versione vecchia di Julius, ma è obbligatorio scaricare questa per fare in modo che le operazioni che seguiranno possano essere effettuate senza errori.
Dopo aver creato il proprio modello acustico, sarà possibile (e verrà descritto), cambiare versione di Julius per utilizzare la più recente e performante.
Il tutorial originale lo trovi su: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/...
Tieni a mente (comunque ti sarà ricordato e spiegato dopo), che per creare modelli acustici seguendo queste istruzioni, non è possibile utilizzare versioni di Julius diverse dalla 3.5.2. Se non viene utilizzata questa versione di Julius arriverai quasi alla fine del tutorial e non riuscirai a concludere il lavoro (non riuscirei a creare l'albero decisionale) e sarai sommerso da incomprensibili messaggi d'errore!
Sacrica Julius 3.5.2 cliccando su questo link: www.repository.voxforge1.org/downloads/software/julius-3.5.2-multipath-win3...
Vai su risorse del computer, poi su C:, poi su cygwin e all'interno della cartella cygwin, crea una nuova cartella e chiamala "Julius" (con la J maiuscola).
Copia il file che hai appena scaricato e che si chiama "julius-3.5-win32bin.zip" e incollalo all'interno della cartella che hai appena creato e chiamato "Julius".
Clicca con il pulsante destro del mouse sul file julius-3.5-win32bin.zip, che hai appena incollato nella cartella Julius, dal menù che si visualizza, seleziona "Extract All" (o qualcosa di simile).
Questo crea all'interno della cartella Julius, tre cartelle: bin, doc e support.
Finito, Julius è installato sul tuo PC. Con Julius sono anche installati:
-Julian (riconoscimento isolato di parole);
-Jcontrol (client per riconoscimento vocale, scritto in C);
-Julius module (Server per il riconoscimento vocale);
-Jclient (client per il riconoscimento vocale, scritto in Perl);
-Adintool (server-client per la gestione di flussi wave su rete internet e lan);
-Ecc,Ecc.
...Continua con l'aggiornamento della path della cygwin e il testing dell'ambiente. [Modificato da calel82 10/09/2012 13:05] |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 10/09/2012 13:44 | |
Aggiornamento path di cygwin, testing dell'ambiente, installazione di Audacity Hai installato HTK e Julius, ora devi fare in modo che la cygwin possa riconoscerli facilmente, così da facilitare anche te nell'utilizzo di entrambi!
8)Aggiornamento della path.
Vai su risorse del computer, poi su C:, poi su cygwin, poi in etc e clicca con il pulsante destro del mouse sopra al file "bash.bashrc", seleziona "apri con" e dall'elenco di programmi scegli "notepad" (o qualcosa di simile).
Ti si apre un editor di testo sul quale leggi una serie di parole chiave.. Portati alla fine del file, ovvero posiziona il cursore del mouse alla fine dell'ultima parola o punteggiatura e premi invio per andare d'accapo.
Copia e incolla quello che segue e sta tra doppie virgolette (ma non copiare anche le doppie virgolette!):
"PATH=/Julius/bin:/HTK/htk-3.3-windows-binary/htk:$PATH
export PATH"
Premi nuovamente invio e salva le modifiche.
Vai in start, poi programmi, poi cygwin e apri cygwin bash shell.
All'interno della cygwin scrivi (E1):
1-scrivi "cd .." (scrivi cd, lascia uno spazio e poi digita due volte il punto) e premi invio;
2-scrivi "dir" e premi invio. Leggerai i nomi di tutte le cartelle e file che contiene il percorso dove ti trovi.. In linea di massima, dovresti leggere anche "etc", se non trovi la cartella "etc", ma altre, scrivi nuovamente "cd .." e premi invio, quindi scrivi di nuovo "dir" e di sicuro leggerai, tra i risultati "etc";
3-scrivi "cd etc" e premi invio;
4-scrivi "dos2unix bash.bashrc" e premi invio.
Finito, hai aggiornato la path della cygwin.
Chiudi la cygwin cliccando sulla X (ics) in alto a destra della finestra, oppure scrivi all'interno della finestra "exit" e premi invio.
9) Testing dell'ambiente.
Se hai appena eseguito il passo 8), allora mi raccomando, chiudi la cygwin, deve essere riavviata..
Premi start, poi programmi, poi cygwin e seleziona cygwin bash shell.
Nella cygwin, scrivi:
1-scrivi "HVite" e premi invio. Verrà visualizzato un messaggio che significa: HTK E' FUNZIONANTE!!!
2-scrivi "julius-3.5.2" e premi invio. Verrà visualizzato un messaggio che significa: JULIUS E' FUNZIONANTE!!!
Se non ti funziona niente, cioè neanche la cygwin dà segni di vita, allora hai commesso un errore nella modifica del file "bash.bashrc".
Per ovviare, riapri tale file e copia all'interno di esso questo che segue tra doppie virgolette, senza doppie virgolette e torna ad (E1):
"# To the extent possible under law, the author(s) have dedicated all
# copyright and related and neighboring rights to this software to the
# public domain worldwide. This software is distributed without any warranty.
# You should have received a copy of the CC0 Public Domain Dedication along
# with this software.
# If not, see .
# base-files version 4.1-1
# /etc/bash.bashrc: executed by bash(1) for interactive shells.
# The latest version as installed by the Cygwin Setup program can
# always be found at /etc/defaults/etc/bash.bashrc
# Modifying /etc/bash.bashrc directly will prevent
# setup from updating it.
# System-wide bashrc file
# Check that we haven't already been sourced.
([[ -z ${CYG_SYS_BASHRC} ]] && CYG_SYS_BASHRC="1") || return
# If not running interactively, don't do anything
[[ "$-" != *i* ]] && return
# Set a default prompt of: user@host and current_directory
PS1='\[\e]0;\w\a\]\n\[\e[32m\]\u@\h \[\e[33m\]\w\[\e[0m\]\n\$ '
# Uncomment to use the terminal colours set in DIR_COLORS
# eval "$(dircolors -b /etc/DIR_COLORS)"
PATH=/Julius/bin:/HTK/htk:$PATH
export PATH
"
( Mi raccomando: dopo l'ultima parola del file, lascia un rigo bianco, altrimenti non funziona proprio niente!)
10)Installazione di Audacity.
Per costruire un modello acustico ci vogliono diverse registrazioni della voce di chi poi effettuerà il riconoscimento vocale, quindi c'è bisogno di un software di registrazione.. Però questo software deve anche essere in grado offrire preferenze di registrazione particolari (come ad esempio la frequenza di campionamento), Audacity, è gratis e ha queste funzionalità.
Vai su audacity.sourceforge.net/download/windows e scaricati l'ultima versione di Audacity. L'ultima versione la riconosci facilmente, perchè è il primo link (che vedi in blu) e che si trova in alto nella pagina, proprio sotto la scritta "Download raccomandati - Ultima versione di Audacity". In particolar modo a te interessa "Audacity 2.0.2 installer", non il downolad .zip.
Esegui il download, clicca sul file appena scaricato e segui la procedura guidata, fino a conclusione.
Vai su start, poi su programmi, poi su Audacity..
Tutto è ormai pronto per creare il tuo modello acustico!
...Continua con la creazione del file rappresentante la grammatica. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 10/09/2012 16:50 | |
1) Primo passo: creazione della grammatica (prima parte).
------------------------------------------------------------------------- Contesto: motore di riconoscimento vocale
Tutti i software di riconoscimento vocale sono costituiti da questi 3 componenti:
- Il modello di linguaggio. Questo componente contiene una lista ordinata alfabeticamente (per Julius) di tutte le parole che il motore di riconoscimento può riconoscere e le relative probabilità di utilizzo. Un altro componente molto legato al modello di linguaggio è la grammatica (o le grammatiche). Una grammatica (o più grammatiche) viene utilizzata per le applicazioni di riconoscimento vocale continuo e veloce, cioè nel dettato. Un file di grammatica, contiene all'interno una o più regole grammaticali, ogni engine ha una serie di parole chiavi e routine stabilita di costruzione della propria grammatica. Il modello di linguaggio è costruito attraverso diverse fasi elaborative e deve essere costruito attraverso l'utilizzo di una fonologia coerente per ogni parola, questa fonologia viene utilizzata per costruire il modello di linguaggio e per Julius, viene espressa attraverso un particolare file, che deve essere perfettamente uguale (come costruzione fonetica e parole contenute) a un altro chiamato lexicon.
- Il modello acustico. Questo è il componente essenziale di qualsiasi motore di riconoscimento vocale ed essenzialmente è un contenitore "intelligente" di esempi vocali (espressi non in formato sonoro, ma in un formato più veloce e più conveniente). Il modello acustico viene creato attraverso l'associazione di ogni forma d'onda sonora al corrispondente fonema (che è in formato testo) e attraverso svariati calcoli matematici e astrazioni concettuali su queste stesse associazioni. In pratica, un modello acustico, almeno per Julius, è un modello nascosto di Markov, che descrive, in maniera più o meno giusta (dipende dalla quantità di frasi esempio), una casistica di parole e le relative forme d'onda più probabili.
- Il decodificatore. Quest'ultimo componente è quello che effettua l'operazione di confronto tra la forma d'onda ascoltata (ciò che dice l'user) e una delle forme d'onda contenute e descritte attraverso il modello acustico. Il confronto viene effettuato fonema per fonema (vedrai che non è proprio così..), a cominciare dal primo rumore catturato dal microfono e finendo con la prima pausa di silenzio. Il confronto non può -per Julius- fallire. Ciò significa che se dici una parola che non hai inserito nel modello acustico, Julius non ti dirà che quella parola non la può riconoscere, ma arrotonderà quella parola a quella più simile che è contenuta nel modello acustico che gli hai dato in pasto.
Dopo il primo rumore e fino alla prima pausa di silenzio, il decodificatore elabora il confronto e stabilisce fonema per fonema (più o meno..) quale parola in formato testo è la più adatta a quella ascoltata e la presenta a video.
------------------------------------------------------------------------- La grammatica.
Una grammatica di riconoscimento non fa altro che preparare l'engine di riconoscimento vocale a una data forma di input. Ovvero, se l'engine deve essere utilizzato per ascoltare frasi fatte da soggetto, verbo e predicato, allora la grammatica ottimale per questa esigenza è proprio quella di SOGGETTO+VERBO+PREDICATO, ovvero, utilizzando le parole chiave che dopo spiegherò, si dovrà dire a Julius:
"aspettati che io ti dica 3 parole per frase, una è un soggetto, una è un verbo e una è un predicato".
Non farti prendere dal panico, non c'è bisogno di arrivare a tanto! Non hai bisogno di seguire uno schema stabilito per parlare. Ti spiegherò un trucchetto che ho letto nel sito di sviluppo di Julius, che ti eviterà tante rogne.. ![[SM=g27990]](https://im0.freeforumzone.it/up/0/90/11615850.gif)
------------------------------------------------------------------------- Come scrivere una grammatica per Julius.
Sia per Julius che per Julian la musica è la stessa. Devi creare due file: in uno ci metti una o più regole grammaticali, in un altro ci metti le parole e la loro fonologia.
Il file dove scrivi la regola grammaticale deve avere l'estensione ".grammar". Julius ha delle parole chiave stabilite per creare una sua grammatica e anche una serie di regole sintattiche. Ancora una volta, sembra una cosa complicatissima, ma è tutto di una facilità estrema, con un semplice esempio capisci tutto..
ESEMPIO DI GRAMMATICA E SPIEGAZIONE (1):
Quella che segue è una grammatica che, se utilizzata, istruisce Julius ad ascoltare una singola parola per volta:
S : NS_B LOOKUP NS_E
Poche parole, ma chiare. Guarda il primo rigo.
La "S :" è la parola chiave d'inizio grammatica, ovvero, va sempre scritta ed è sempre la stessa, non c'è niente da capire, Julius ti impone di scrivere sempre come prima cosa "S :" (e puoi pure non metterci lo spazio!).
Continua a leggere. "NS_B" è un acronimo di "NoiSe Begin", quindi già capisci che rappresenta il silenzio che precede il primo rumore (rumore nel senso stretto del termine e anche nel senso di onde sonore, quindi parlato). Niente da riflettere fin ora, hai già capito che il decodificatore comincia a lavorare che c'è silenzio e che aspetta il primo rumore..
Continua a leggere.. "LOOKUP" è una variabile, ovvero è un qualcosa che richiama un valore non predicibile a priori, che, appunto, è una parola ascoltata! "NS_E" è l'acronimo di "NoiSe End".
Quindi senza sapere niente di quello che concerne il complicato linguaggio adottato da Julius per le grammatiche, tu hai già capito che il primo rigo della grammatica descritta dice a Julius:
"Aspettati SILENZIO seguito da PAROLA seguito da SILENZIO".
Praticamente a Julius viene detto che sarà utilizzato per riconoscere una singola parola alla volta..
ESEMPIO DI GRAMMATICA E SPIEGAZIONE (2):
Quella che segue è una grammatica che, se utilizzata, istruisce Julius ad ascoltare due parole per volta:
S : NS_B LOOKUP NS_E
LOOKUP: CONNECT NAME
Magia! Il rigo di sopra è identico.. No, il rigo di sotto fa cambiare quello di sopra... Infatti se nel rigo di sopra ho detto a Julius di aspettarsi qualcosa del genere:
SILENZIO seguito da PAROLA seguito da SILENZIO
dopo gli scrivo:
PAROLA: PRIMAPAROLA SECONDAPAROLA
Ovvero "LOOKUP: CONNECT NAME" equivale a dire LOOKUP è fatto da CONNECT e da NAME.
Quindi è come se avessi scritto:
S : NS_B CONNECT NAME NS_E
Difficile? Non credo!
..Continua con la spiegazione del .voca e di come si lega al .grammar. [Modificato da calel82 15/04/2013 16:19] |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 25/04/2013 16:25 | |
PREPARAZIONE DEI DATI:
Spiegazione del .voca e di come si lega al .grammar.
Per questo tutorial useremo una grammatica diversa da quella che utilizza il tutorial di voxforge. Questo perchè non vogliamo utilizzare un riconoscimento di frasi note e che hanno sempre la stessa struttura, ma vogliamo che Julius (non Julian) riconosca qualsiasi tipo di frase.
Nel sito dove è possibile scaricare Julius, troviamo anche tutta la documentazione relativa all'engine, tra le varie cose, troviamo anche un tutorial che spiega come utilizzare le grammatiche.
Qui trovate il tutorial sulle grammatiche di Julius:
http://julius.sourceforge.jp/en_index.php?q=en_grammar.html
Tra le varie grammatiche troviamo questa:
S: NS_B WORD_LOOP NS_E
WORD_LOOP: WORD_LOOP WORD
WORD_LOOP: WORD
La grammatica (o le grammatiche) che vengono utilizzate per il riconoscimento vocale hanno un grosso impatto sulla prestazione di Julius e sono importantissime per ottenere un buon riconoscimento.
Diamo un occhio veloce a questa grammatica:
(primo rigo) S: NS_B WORD_LOOP NS_E
Con questo rigo diciamo a Julius di aspettarsi che lo speaker dica nell'ordine:
1° parola: una qualsiasi parola contenuta nell'insieme "NS_B";
2° parola: una qualsiasi parola contenuta nell'insieme "WORD_LOOP";
3° parola: una qualsiasi parola contenuta nell'insieme "NS_E".
(secondo rigo) WORD_LOOP: WORD_LOOP WORD
Ora diciamo a Julius che nell'insieme di parole chiamato "WORD_LOOP", ci troverà nuovamente l'insieme "WORD_LOOP" e dopo l'insieme di parole chiamato "WORD".
(terzo rigo) WORD_LOOP: WORD
In ultimo diciamo che l'insieme di parole chiamato "WORD_LOOP" è esattamente identico all'insieme di parole chiamato "WORD".
TRADOTTO:
Abbiamo semplicemente detto a Julius aspettati un minimo di due parole anche uguali e un massimo di innumerabili parole (da due a quante ne dice lo speaker).. Niente di più!
Ora basta chiacchiere e cominciamo a costruire il modello acustico!
Aprire Risorse del computer, poi C:, poi cygwin, poi home e aprire la cartella che si chiama come il proprietario del computer, oppure con il nome del computer (se non avete giocato con la cygwin, dovreste trovare sempre e solo 1 cartella, è quella non potete sbagliare!).
Dentro questa cartella createne un'altra e chiamatela "voxforge", dentro la cartella voxforge, createne un'altra e chiamatela "manual".
Ora possiamo creare il file .grammar.
Cliccare all'interno della cartella manual con il pulsante destro e selezionate "Nuovo" e poi "nuovo documento di testo".
Si creerà un nuovo documento dal nome "nuovo documento.txt".
Rinominatelo sample.grammar.
(Subito dopo aver creato il nuovo file di testo, l'icona del nuovo file dovrebbe essere già pronta per essere rinominata e vi basta scrivere il nuovo nome. Nel caso non succeda o abbiate difficoltà, basta cliccare con il pulsante destro del mouse sopra al file appena creato e scegliere "Rinomina")
Dopo aver rinominato il file, potreste visualizzare un messaggio tipo "voi cambiare l'estensione?", la vostra risposta deve essere SI ;-)
All'interno del file sample.grammar, incollate le righe seguenti, contenute tra doppi apici (senza copiare i doppi apici):
"S: NS_B WORD_LOOP NS_E
WORD_LOOP: WORD_LOOP WORD
WORD_LOOP: WORD"
Salvate il file e chiudetelo.
Il file così creato è in codifica Windows, ma a noi serve in codifica Unix, quindi dobbiamo convertirlo con uno strumento che si chiama dos2unix.
Apriamo "risorse del computer", poi C: e cygwin.
Tra le icone cliccate sulla terz'ultima che dovrebbe chiamarsi "cygwin.bat", oppure un qualsiasi nome ma sempre .bat.
Questa procedura attiva la cygwin.
Di default vi trovate in C:/cygwin/home/nomeUtente/ e dovete raggiungere C:/cygwin/home/nomeUtente/voxforge/manual/.
Quindi scrivete dentro la cygwin:
cd voxforge (poi premere invio)
cd manual (poi premere invio)
dos2unix sample.grammar (poi premere invio)
Così abbiamo convertito il file sample.grammar in formato Unix e possiamo utilizzarlo senza problemi in ambiente Unix.
Nel grammar file abbiamo dichiarato di voler utilizzare 3 insiemi (categorie) di parole: NS_B, WORD_LOOP e NS_E.
Ora dobbiamo comunicare a Julius quali parole fanno parte di ciascun insieme (categoria). Per farlo utilizziamo un file che deve avere estensione .voca.
Il grammar file e il voca file esprimono concetti legati tra loro, quindi è buona norma che abbiano lo stesso nome!
Se il grammar file lo abbiamo chiamato sample.grammar, allora il voca file lo chiameremo sample.voca.
Ma come va costruito il voca file?
C'è una sintassi specifica da seguire, questa sintassi è obbligatoria per poter far funzionare Julius e tutti gli strumenti HTK che utilizzeremo..
Consideriamo nuovamente la riga S: NS_B WORD_LOOP NS_E
-"S:" è una parola chiave che ha il significato: quello che segue è la mia frase;
-"NS_B" è la prima parola della mia frase. Questa parola è contenuta nell'insieme (categoria) che si chiama "NS_B";
-"WORD_LOOP" è la seconda parola (oppure tante parole) della mia frase. Questa parola (oppure queste parole), sono contenute nell'insieme chiamato "WORD_LOOP";
-"NS_E" è la terza e ultima parola della mia frase. Questa parola è contenuta nella categoria chiamata "NS_E".
Le liste di parole, oppure insiemi, oppure come volete chiamarle voi, non sono altro che un gruppo di parole, il cui gruppo è identificato dall'etichetta "NS_B", "WORD_LOOP" oppure "NS_E".
A sua volta "WORD_LOOP" viene completamente descritta da "WORD", nel rigo: WORD_LOOP: WORD
Ora queste categorie, queste liste, vanno specificate per bene!
Un esempio di come specificare una lista può essere:
data la grammatica: "S: NS_B NOME COGNOME TELEFONO NS_E"
NOME: (in stampatello il nome della lista e in piccolo i componenti)
Carlo
Michele
Francesco
COGNOME:
Rossi
Bianchi
Gialli
TELEFONO:
tretretrecinquequattrotre
tredueottoquattrotresette
treottonoveunounotrecinque
Questo non basta, a Julius servono anche i fonemi che costruiscono i suoni delle parole:
NOME:
Carlo k a r l o
Michele m i k e l e
Francesco f r a n ci e s k o
ecc ecc
Questo è il primo passaggio su cui bisogna fare attenzione!
Perchè si può scegliere qualsiasi simbolo per rappresentare un dato suono, ma poi quel simbolo deve essere utilizzato per tutte le occorrenze del suono considerato. Un errore di distrazione non verrà rilevato nei passi successivi e renderà il riconoscimento vocale PESSIMO!
Indipendentemente dalle parole che voi sceglierete, in questo tutorial si utilizzerà il seguente modello fonetico:
///////CORRISPONDENZA SIMBOLI SCELTI-FONEMI
/////// "GHL+consonante" --> ʎ di glicine
/////// "GL+vocale" --> ʎ di maglia
/////// "SCH+consonante" --> sk di scala
/////// "SC+e oppure +i" --> ʃ di ascia
/////// "B" --> b di buco
/////// "CI+e oppure +i" --> tʃ di cena
/////// "K+consonate oppure +a oppure +o oppure +u" --> k di cane
/////// "D" --> d di dado
/////// "F" --> f di farfalla
/////// "GO" --> g di gola
/////// "GG" --> dʒ di gelo e giglio
/////// "G" --> NOsimbolo di aggiungere
/////// "GH" --> g di ghiaccio
/////// "GN" --> ɲ di vigna
/////// "H" --> NOsimbolo di ha
/////// "I" --> j di ieri
/////// "L" --> l di lana
/////// "M" --> m di mela
/////// "NF" --> ɱ di anfora
/////// "NC" --> ŋ di anche
/////// "N" --> n m rispettivamente di nano e di un pò
/////// "P" --> p di pera
/////// "Q" --> k di quattro
/////// "R" --> r di raro
/////// "S" --> S di sale
/////// "T" --> t di topo
/////// "U" --> w di uomo
/////// "V" --> v di vero
/////// "Z" --> dz di zero
/////// "ZI" --> ts di azione
/////// "W" --> NOsimbolo di wresling
/////// "Y" --> NOsimbolo di yogurt
/////// "J" --> NOsimbolo di job
/////// "X" --> Nosimbolo di xilofono
/////// "EE" --> EE Verbo essere terza persona singolare presente indicativo.
Vi consiglio di utilizzare la mia tabella, perchè ho creato uno strumento che crea in automatico il voca file utilizzando questa struttura fonetica.. Ad ogni modo potete creare la vostra corrispondenza fonetica e utilizzare quella che preferite.
Dovete stare attenti solo al fatto che Julius e l'HTK non lavorano con lettere accentate. Le lettere accentate sono vietate!
Non è un problema se non per la "è", che ha una pronuncia decisamente diversa dalla "e". Per distinguerla, io uso la "EE".
Usando la mia tabella, quando effettuerete il riconoscimento vocale non leggerete da Julius "UNIVERSITA'" ma "UNIVERSITA" e la "E'" la leggerete "EE". In pratica, non si possono utilizzare lettere accentate nè in minuscolo, nè in maiuscolo.
Quindi utilizziamo una corrispondenza tra pronuncia e fonemi per descrivere ogni parola che vogliamo utilizzare e che dobbiamo scrivere nel file sample.voca.
Oltre a questo, dobbiamo rispettare la sintassi HTK.
Semplicemente, la sintassi HTK, ci dice che:
-Il nome delle categorie deve essere stampatello e preceduto dal simbolo "%";
-Le parole contenute nelle liste possono essere sia stampatello che minuscolo (ma in questo tutorial si userà lo stampatello);
-I fonemi devono essere divisi dallo spazio e possono essere sia minuscoli che maiuscoli (qui li scriviamo minuscoli).
ESEMPIO:
%NOME
CARLO k a r l o
MICHELE m i k e l e
MARIO m a r i o
Con un esempio pratico tutto sarà più chiaro...
Torniamo alla cartella manual che abbiamo creato prima e con lo stesso procedimento usato per creare il nuovo file "sample.grammar", creiamo il file "sample.voca".
Dentro al file sample.voca scriviamo prima quello che segue tra virgolette (senza le virgolette!), purtroppo non posso scrivere direttamente il codice, altrimenti viene interpretato da ffz.. Quindi scrivete esattamente quel che segue, ma non scrivete il simbolo "-", al posto del trattino non scriveteci niente:
"%NS_B
<-s->- sil
%NS_E
<-/-s-> sil
%WORD"
(fate riferimento a quello che sta scritto qui www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/data-pre... al paragrafo ".voca" dove comincia il tutorial)
Starete pensando.. Che cos'è ora quel "sil"?
Semplicemente NS_B sta per new sentence begin, ovvero "inizio della nuova frase", mentre NS_E "new sentence end".
Prima che si parla al microfono, c'è silenzio. Per cui l'ascolto del silenzio fa capire a Julius che sta per cominciare una nuova frase.
Dopo aver finito di parlare, c'è nuovamente silenzio.
E il fonema "sil" è l'astrazione del silenzio.
Quindi la nostra grammatica viene vista da Julius:
SILENZIO (almeno due parole) SILENZIO.
In realtà il discorso è molto complesso, ma basta sapere questo!
Dopo %WORD scrivete le parole che vorreste far "imparare" a Julius.
Giusto come esempio ne scriverò qualcuna, voi seguite il mio procedimento ma scrivete tutte le parole che volete!
Ecco il contenuto completo del file sample.voca (non copiate le virgolette!):
"%NS_B
sil
%NS_E
sil
%WORD
CARLO k a r l o
ARANCIA a r a n ci a
TASTIERA t a s t i e r a"
Le parole possono essere scritte in un qualsiasi ordine, basta che ci sia una sola parola per rigo.
Se decidete di far riconoscere a Julius meno di 500 parole, tenete presente che dovrete ripetere (con il training, che verrà descritto più avanti) ogni parola almeno 20 volte. Se ne vorrete scrivere tra 500 e 2000, dovrete ripetere ogni parola almeno 45 volte!
Dopo aver scritto tutte le parole che volete, salvate il file e chiudetelo.
Aprite la cygwin come ho descritto sopra, quindi nella cygwin scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix sample.voca (invio)
mkdfa.pl sample (invio)
L'ultimo comando serve a compilare i due file costruiti e crearne altri che ci serviranno dopo... Se non avete fatto errori dovreste leggere sulla cygwin:
---
Now parsing grammar file
Now modifying grammar to minimize states[-1]
Now parsing vocabulary file
Now making nondeterministic finite automaton[6/6]
Now making deterministic finite automaton[6/6]
Now making triplet list[6/6]
---
generated: sample.dfa sample.term sample.dict
Dovreste trovarvi a meno dei numeri tra parentesi quadre (anche se sono gli stessi non è un problema)!
Il comando di sopra vi ha creato tre file in C:/cygwin/home/nomeUtente/voxforge/manual/
questi file sono:
-sample.dfa
-sample.dict
-sample.term
Avete appena concluso lo step descritto qui:
www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/data-pre...
...Segue con la creazione del dizionario delle pronunce... [Modificato da calel82 25/04/2013 16:34] |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 27/04/2013 16:21 | |
DIZIONARIO DELLE PRONUNCE
Un dizionario delle pronunce non è altro che una lista ordinata di corrispondenze tra parole e relative pronunce. Oppure, se preferite, una lista ordinata che specifica univocamente per ogni fonema la data pronuncia e per ogni parola la corrispondente pronuncia.
In pratica, quando noi parliamo, muoviamo corde vocali, labbra e lingua tagliando l'aria ed emettendo flussi d'aria.
La nostra voce, non viene generata in maniera diversa dal suono di una corda di chitarra che viene pizzicata!
Il suono, sia esso generato da un essere umano che da una macchina, non è altro che una variazione di pressione dell'aria.
Il nostro scopo è quello di catturare la variazione di pressione dell'aria (il suono, le parole dello speaker), analizzarlo e capire quel suono a quale parola inserita nel .voca corrisponde. Trovata una corrispondenza, dobbiamo prendere la parola e stamparla a video.
Heheh questo lo fa Julius non noi, ma noi dobbiamo dare a Julius tutto quello che gli serve per poter fare questo lavoraccio!
Quando noi sentiamo una canzone che conosciamo per radio, siamo in grado di canticchiarla e seguirne il ritmo. Perchè?
Semplicemente perchè abbiamo "in memoria" la canzone, quindi il nostro cervello quando sente la canzone in questione, in automatico effettua una ricerca in memoria. Come la effettua?
Potete immaginare questa ricerca come la ricerca all'interno di un "DIZIONARIO DELLE CANZONI", che è così composto:
Titolo Canzone - - - canzone in formato mp3
ONE LAST KISS - - - oneLastKiss.mp3
BARCELLONA - - - barcellona.mp3
Dato questo dizionario delle canzoni, il cervello che ha analizza questo file, non fa altro che ascoltare dalle orecchie qualche secondo di una canzone passata dalla radio, convertire questa porzione di canzone in mp3 e confrontarla con tutti i file .mp3 contenuti nel dizionario.
Se trova corrispondenza di dati, rende disponibile il titolo.. E lo stampa "a pensiero" ;-)
Julius deve fare una cosa più semplice: deve ascoltare le parole dette a microfono e capire come si scrivono.
Il dizionario delle pronunce può essere pensato così:
ParolaScritta - - - SuonoParola
Carlo - - - onda sonora rapp. la pronuncia della parola Carlo
Per costruire questa lista, che è più opportuno chiamare "struttura dati", dobbiamo utilizzare l'HTK e quindi siamo legati ad utilizzare parole chiave e routine specifiche per il nostro scopo.
Come avrete intuito, ci servono esempi sonori ed esempi testuali, queste due cose, poi, le dobbiamo dare in pasto a uno strumento che ci caccia il dizionario delle pronunce.
Basta con la teoria, mettiamoci a lavoro.
Aprite risorse del computer, poi C:, poi cygwin, poi home, poi la cartella nomeUtente, quindi aprite voxforge e in fine manual.
All'interno di manual create il nuovo file prompts.txt.
Dentro il file prompts.txt tutto deve essere scritto secondo questo standard:
*/sampleNumero (spazio)PAROLA1 (spazio)PAROLA2 ....(spazio)PAROLA12
ES:
*/sample1 PER FAVORE ACCENDI LA LUCE E CHIUDI LA PORTA DIECI UNDICI DODICI
*/sample2 QUANDO FUORI PIOVE EE BELLO STARE A CASA NOVE DIECI UNDICI E
Ogni "sample" deve stare su di un solo rigo.
Ogni "sample" deve avere 12 parole (sul tutorial voxforge viene consigliato di utilizzarne tra 8 e 10, ma io ho misurato prestazioni migliori utilizzandone 12).
Ogni "sample" deve contenere parole che sono contenute nel file sample.voca.
Ogni "sample" può avere parole ripetute più volte, anche 12 tutte uguali.
Ogni "sample" ha il suo numero diverso dagli altri.
Se avete scritto nel file sample.voca meno di 500 parole, se volete un riconoscimento decente, dovete costruire il file prompts.txt, in modo da ripete almeno 20 volte ogni parola.
Dopo aver finito di scrivere tutti i "sample", chiudete il file e salvatelo.
Aprite quindi la cygwin e scrivete dentro:
cd voxforge (invio)
cd manual (invio)
dos2unix prompts.txt (invio)
perl ../HTK_scripts/prompts2wlist prompts wlist (invio)
Questo vi avrà creato un file dal nome "wlist" nella cartella manual.
Aprite il file wlist, cliccando sopra con il pulsante destro e scegliendo apri, poi, seleziona da un elenco e quindi applicazione notepad.
Vedrete che wlist non è altro che la lista delle parole che voi avete deciso di utilizzare ma ordinata in ordine alfabetico.
Seguendo l'ordine alfabetico aggiungete a questa lista i seguenti due righi:
SENT-END
SENT-START
Salvate il file wlist e chiudetelo.
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix wlist (invio)
Ora abbiamo la lista di parole che deve essere la parte testuale del nostro dizionario delle pronunce.
Aprite il file sample.voca e lasciatelo aperto.
Andate in risorse del computer, poi C:, poi cygwin, poi home, poi nomeUtente e aprite la cartella voxforge.
All'interno della cartella voxforge, createne un'altra e chiamatela "lexicon".
Dentro la cartella lexicon create un nuovo file e chiamatelo "voxforge_lexicon.txt".
Aprite il file voxforge_lexicon.txt e lasciatelo aperto.
Copiate per intero il contenuto del file sample.voca e incollatelo nel file voxforge_lexicon.txt.
Bisogna apportare delle modifiche manualmente al file voxforge_lexicon.txt così ottenuto, ecco le modifiche da fare:
1-Cancellate da %NS_B a %WORD, devono rimanere solo le parole e i rispettivi fonemi;
2-Ordinate alfabeticamente tutte le parole;
3-Per ogni riga, riscrivete tra la parola e i fonemi, la stessa parola tra parentesi quadre.
ES:
CARLO [CARLO] k a r l o
MICHELE [MICHELE] m i k e l e
4-Inserite nell'elenco di parole, sempre rispettando l'ordine alfabetico le seguenti righe tra doppi apici (senza copiare i doppi apici):
SENT-END [] sil
SENT-START [] sil
Salvate il file e chiudetelo. Aprite la cygwin e scrivete:
cd voxforge (invio)
cd lexicon (invio)
dos2unix voxforge_lexicon.txt (invio)
Aprite risorse del computer, C:,cygwin, home, nomeUtente, voxforge e in fine manual.
Dentro la cartella manual create un nuovo file e chiamatelo global.ded.
Dentro al file global.ded scrivete il seguente testo tra doppi apici (senza copiare i doppi apici):
"AS sp
RS cmu
MP sil sil sp"
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix global.ded (invio)
HDMan -A -D -T 1 -m -w wlist -n monophones1 -i -l dlog dict ../lexicon/voxforge_lexicon.txt (invio)
Il file global.ded non è altro che un file che contiene informazioni di elaborazione. Queste informazioni sono scritte in parole chiave dell'HTK e servono per far elaborare da HDMan quel che a noi serve per creare un dizionario delle pronunce che può essere utilizzato da Julius.
HDMan è uno strumento messo a disposizione dall'HTK, che crea due file, in uno ci scrive le informazioni relative alla grammatica che utilizziamo e alla costruzione fonetica delle parole. E un altro file dove ci scrive semplicemente una lista di fonemi (che sono i fonemi che noi utilizziamo).
Con l'istruzione che abbiamo scritto nella cygwin, abbiamo comandato a HDMan di creare 3 file.
-dlog: che contiene la lista di fonemi che fanno parte del nostro dizionario delle pronunce;
-dict: che contiene informazioni legate sia alla grammatica che alle parole che abbiamo decido di utilizzare;
-monophones1: che contiene la lista di fonemi del nostro modello acustico.
Sarebbe buona norma leggere il file dlog e controllare il bilanciamento del modello fonetico.. Fatta eccezione per il fonema "sil", tutti gli altri fonemi devono esserci con un'occorrenza di 3-5 volte. Tuttavia Julius funziona bene anche con dizionari delle pronunce che presentano occorrenze di fonemi singole.
Per procedere alla creazione del modello acustico, ora dobbiamo utilizzare i modelli nascosti di Markov.
Procederemo gradualmente, creando via via modelli sempre più accurati.
Sono i modelli nascosti di Markov che noi creeremo che poi verranno utilizzati da Julius per il riconoscimento vocale!
Questi modelli sono strutture dati molto complesse e vengono utilizzate per effettuare calcoli statistici predittivi.
Julius li utilizza per elaborare i suoni sentiti e stabilire che parola stampare a video.
Cominciamo con elaborare modelli nascosti di Markov descriventi singoli fonemi e leghiamo le parole alla sequenza corrispondente di fonemi.
In pratica... Ragazzi è semplice, non pensate ai numeri ma agli effetti! Mi spiego meglio.. Almeno ci provo!
Immaginate di avere un pappagallo e di volergli insegnare la parola "Ciao".
Cosa fate? Bhè vi avvicinate al pappagallo e gli ripetete in continuazione tanti "sample" vocali di "Ciao", fino a che lui (heheheh) "statisticamente" non capisce che per farvi stare zitti deve dire "Ciao".
Ecco quello che succede nella testa del pappagallo è quello che fa un modello nascosto di Markov.
Dato un suono qualsiasi, un modello nascosto di Markov, in base agli esempi con cui è stato creato, statisticamente avanza stime sul corrispondente testo.
ES:
prendo tutto il file prompts.txt, prendo file sonori che sono le parole contenute nel prompts.txt lette ad alta voce e registrate, li metto dentro un modello nascosto di Markov e dico a questo aggeggio:
"Ti ho dato da una parte le onde sonore e dall'altra quello che voglio che tu scriva quando senti le corrispondenti onde. Ora lavora schiavo."
Non possiamo creare modelli nascosti direttamente per frasi, Julius non li riconoscerebbe!
Dobbiamo seguire una serie di passaggi per arrivare a modelli nascosti di triplici fonemi (ne parleremo in seguito...).
Il primo passo è quello di creare modelli nascosti che riconoscano fonemi.
ES:
io dico un singolo fonema tra quelli del mio modello e gli HMMs (Hidden Markov Models), elaborano statisticamente il fonema che ho pronunciato e quelli che ha in memoria, per capire che fonema ho detto.
Quindi creeremo un HMM per ogni fonema.
Apriamo risorse del computer, poi C:, poi cygwin, poi home, poi nomeUtente, poi voxforge ed in fine manual.
Copiamo il file monophones1 cliccando con il pulsante destro del mouse sopra lo stesso file e selezionando la voce "copia", poi cliccando con il pulsante destro del mouse in un punto (che non sia il nome di un altro file) all'interno della cartella "manual" e selezioniamo la voce "incolla".
Rinominiamo la copia di monophones1 appena incollata e chiamiamola "monophones0" (senza doppie virgolette).
Apriamo il file monophone0 e cancelliamo il fonema "sp".
ES:
monophones0 prima:
a
b
ci
sp
k
...
monophones0 dopo:
a
b
ci
k
...
Semplicemente dopo aver rinominato la copia di monophones1 in monophones0, apriamo monophones0, cerchiamo dove sta il rigo con scritto "sp" e lo cancelliamo, restando inalterato il resto del file.
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix monophone0 (invio)
Avete appena terminato lo step 2 del tutorial di voxforge che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/data-pre...
.. Nel prossimo post spiegherò come registrare gli esempi sonori che verranno utilizzati per "caricare" gli HMMs.. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 29/04/2013 15:25 | |
Per creare il nostro dizionario delle pronunce, ovviamente... Servono pronunce!
Utilizzeremo le registrazioni sonore delle frasi che abbiamo scritto nel file prompts.txt. Per registrarle utilizzeremo il software Audacity.
La registrazione deve avvenire in un luogo quanto più silenzioso e a casse spente. Se questi due requisiti non vengono soddisfatti, il riconoscimento di Julius sarà pessimo!
Bisogna, inoltre, fare un pelino di attenzione a come si parla vicino al microfono.
Se si utilizza un microfono fisso (da scrivania), questo va posizionato in modo da avere la bocca almeno a 2 cm dallo stesso.
Se si utilizza un radiomicrofono a clip (quelli che vengono usati per le interviste), questo va posizionato su di un supporto fisso, che vi possa permettere di parlare sempre alla stessa distanza dallo stesso (distanza che non deve essere minore di 12-13 cm).
Se si utilizza un microfono ad archetto (di quelli con cuffie da call center), si deve fare attenzione che il microfonino alla fine dell'archetto non tocchi nè labbra, nè guance e che si trovi a una distanza di almeno 1,5 cm dalla bocca.
Sconsiglio l'utilizzo di radiomicrofoni a clip, sono poco direttivi e catturano troppi rumori (tipo il sibilo della ventola del processore..).
Aprire Audacity, in alto nella parte centrale dello schermo vedrete il simboletto del microfono, portare il volume del microfono a 1.
Se si sta utilizzando un computer fisso, staccare le casse, altrimenti aprire il controllo del volume e selezionare "mute".
La prima cosa da fare è ridimensionare la finestra di Audacity, in modo da coprire la metà superiore dello schermo.
Aprire quindi risorse del computer, poi C:, poi cygwin, poi home, poi manual e quindi il file prompts.txt.
Aprite la cygwin (sta spiegato nel post precedente come fare) e scrivete:
cd voxfoge (invio)
cd manual (invio)
unix2dos prompts.txt (invio)
Chiudete la cygwin.
Aprite risorse del computer, poi C:, poi cygwin, poi home, poi nomeUtente, poi voxforge.
Dentro la cartella voxforge creare una nuova cartella e chiamarla train. Dentro la cartella train, creare una nuova cartella e chiamarla wav.
Premete "start", accessori, controllo volume e alzate il volume del microfono al massimo. Chiudete il controllo del volume.
Aprite risprse del computer, poi C:,poi cygwin, poi home, poi nomeUtente, poi voxforge, poi manual, quindi prompts.txt.
Ridimensionate la finestra in modo da farle occupare l'altra metà di schermo libera.
Alla fine dell'operazione dovreste vedere il vostro schermo diviso in due. Nella parte superiore Audacity, in quella inferiore il file prompts.txt.
Selezionate la finestra di audacity, cliccando in un punto qualsiasi di essa, quindi posizionatevi come ho descritto sopra, vicino al microfono e premete "record" (il cerchietto rosso).
Provate a parlare dicendo sempre una sola parola, noterete che mentre viene registrata la vostra voce, vengono visualizzate anche le rispettive onde sonore.
Dovreste vedere due forme d'onda perfettamente uguali, consideratene solo una, quella di sopra (se ne vedete una o più di due, poco male.. considerate sempre e solo la prima!).
Le onde che vedete sono disegnate su un diagramma in cui l'asse orizzontale rappresenta il tempo, mentre quello verticale rappresenta l'intensità.
Nell'istante in cui voi premete "record", viene visualizzato il diagramma di variazione della pressione dell'aria rispetto al tempo.
Premete "stop".
Premete e tenete premuto il pulsante "Ctrl" della tastiera e premete il pulsante "z", avete così annullato la registrazione prima effettuata.
Provate a premere il pulsante "record" e dire "CIAO", quindi premete subito "stop". Notate i numeri che leggete a sinistra del diagramma:
1
0.5
0
-0.5
-1
E' importante confrontare le onde che abbiamo registrato con questi valori.. L'onda della registrazione appena effettuata parte da un valore prossimo allo zero e poi ha picchi negativi (in direzione -1) e positivi (in direzione 1), per poi tornare ad avere un valore prossimo allo zero.
In pratica, il valore prossimo allo zero è il valore "silenzio", se non lo vedete in prossimità dello zero ma più in giù (verso -1), allora abbassate leggermente il volume del microfono di Audacity, provate nuovamente e, nel caso l'onda non sia in prossimità dello zero, continuate ad abbassare il volume.
Se, al contrario, lo misurate più alto, allora state utilizzando un radiomicrofono; entrate nel menù del trasmettitore e selezionate "sensibilità", quindi impostatela a -30db e salvate le impostazioni (nel caso il valore dell'onda sia ancora più sotto dello zero, allora diminuite ancora la sensibilità: -33db, -36db..ecc).
Dopo esservi assicurati che in condizioni di silenzio, l'onda sonora che disegna Audacity, sia in prossimità dello zero, controllate i picchi positivi (verso 1) e negativi (verso -1) dell'onda della parola "Ciao".
Se i picchi toccano il valore 1 oppure -1, dovete allontanare la bocca dal microfono di 1 cm (se prima stavate a 2 cm, ora posizionatevi a 3, spostando voi la testa, oppure spostando il microfono, oppure regolando il braccetto dello stesso microfono).
La parte recettiva del microfono deve essere messa in direzione orientata verso la bocca e non verso il naso e bisogna respirar piano, in modo da non far catturare al microfono il rumore del respiro.
Provate e riprovate fino a quando l'onda che rappresenta il vostro silenzio non si trova a zero e fino a quando, pur parlando con tono normale, le onde, non tocchino mai -1 e 1.
Ora è possibile cominciare il training, ovvero la registrazione degli esempi sonori.
Mantenete sempre la stessa distanza e lo stesso tono di voce durante tutto il procedimento che segue.
Se nella finestra di Audacity vedete una registrazione, premete e tenete premuto il pulsante "Ctrl" e dopo premete "z", in modo da pulire la registrazione.
Posizionate il cursore sul primo rigo del file prompts.txt, in modo da tenere traccia di dove vi trovate (procedendo con il training è facile fare errori di distrazione, meglio evitare!).
Premere "record" su Audacity e leggere ad alta voce le parole contenute nel "sample" corrente.
Abbiate cura di aspettare 1 secondo prima di cominciare a leggere la prima parola, leggere le parole intervallandole costantemente di almeno 1 secondo e di aspettare un secondo tra la lettura dell'ultima parola e la pressione del pulsante "stop".
ES:
rigo del file prompts.txt */sample1 LEGGIMI CON TONO DI VOCE NORMALE
registrazione:
premi "record", aspetta un secondo, leggi la parola "LEGGIMI", aspetta 1 secondo, leggi la parola "CON", aspetta 1 secondo, leggi "TONO", aspetta 1 secondo, ...., leggi "NORMALE", aspetta 1 secondo e premi "stop".
Dopo aver premuto stop premere il pulsante "file" di Audacity, selezionare "Esporta..", verrà chiesto il nome con cui salvare il file, scrivere sampleNumero:
ES:
rigo prompts.txt */sample1 LEGGIMI CON TONO DI VOCE NORMALE
nome da scrivere quando si esporta il file sonoro con Audacity: sample1
rigo prompts.txt */sample2 LEGGIMI ANCORA CON TONO DI VOCE NORMALE
nome da scrivere quando si esporta il file sonoro con Audacity: sample2
Dopo aver scritto il nome del file da esportare come descritto sopra, controllare che lo stesso file venga salvato nel percorso C:/cygwin/home/nomeUtente/voxforge/train/wav/
Finita la registrazione del primo rigo del prompts.txt, seguire le seguenti istruzioni:
Passo 1 - Posizionare il cursore del mouse sull'esempio di prompts.txt seguente a quello appena registrato;
Passo 2 - Premere e tenere premuto il tasto "Ctrl" e premere il tasto "z";
Passo 3 - Premere "record" in Audacity e leggere la frase di prompt come descritto prima;
Passo 4 - Premere "file" in Audacity, poi "Esporta..", salvare il file come descritto prima;
passo 5 - se ci sono altri "sample" da registrare, tornare al "Passo 1", altrimenti chiudere Audacity e il file prompts.txt, quindi aprire la cygwin e scrivere:
cd voxforge (invio)
cd manual (invio)
dos2unix prompts.txt (invio)
Avete appena concluso lo Step 3 del tutorial voxforge, che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/data-pre...
Rispetto al tutorial originale, non avete impostato nessun particolare valore in Audacity, nè la frequenza di campionamento, nè i canali di registrazione.
A differenza di quel che viene scritto nel tutorial voxforge per Julian, per Julius. le cose sono un pelino diverse.
Julian è solo una sotto-funzione di Julius, Julius è molto più veloce e preciso!
Anche se il tutorial di voxforge suggerisce un campionamento a 48000 Hz, noi lo abbiamo utilizzato a 44100Hz, che è la stessa frequenza di campionamento che viene utilizzata per le onde sonore che poi vengono incise sui comuni CD audio (che sono in formato .wav, come quelli che abbiamo creato noi), direi che come precisione è più che sufficiente.
Inoltre, non abbiamo bisogno di complicarci la vita nella scelta del numero di canali per la registrazione del training, semplicemente perchè dopo in maniera facilissima diremo all'HTK di considerare un solo canale.
.. Continua con la creazione dei file di trascrizione.. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 04/05/2013 12:45 | |
Il nostro dizionario delle pronunce ha tutto quello che serve per essere montato e utilizzato da Julius:
- Abbiamo la pronuncia delle parole;
- Abbiamo il corrispondente testo.
Ora dobbiamo creare uno strumento che "associa" ad ogni parola in formato testo, la corrispondente pronuncia (o suono).
Questo strumento, non conviene che ce lo inventiamo noi, ma conviene che ce lo ricaviamo attraverso l'Hidden Markov Model Toolkit (HTK).
Però l'HTK ha bisogno di ulteriori elaborazioni dei dati che abbiamo creato. In particolar modo, non possiamo dare direttamente il nostro prompts.txt e i corrispondenti file wave come input alle funzioni HTK, non saprebbero che farsene!
L'HTK, per associare un suono a un testo, lavora con file di etichette (label file). Questi label file vengono interpretati da alcune specifiche funzioni e associati in maniera opportuna al suono pertinente. Cosa sono i label file?
Sono dei file di testo che hanno una struttura del tipo:
"sample1.lab"
CARLO
SCRIVE
..
"sample2.lab"
CIAO
COME
STAI
..
L'HTK possiede delle routine che sono in grado di analizzare le onde sonore, riconoscendo e isolando i fonemi. Un label file funge da guida nell'associazione tra sample sonori e sample testuali. Niente di più.
Creiamo quindi il nostro primo label file a partire dal nostro prompts.txt.
Aprire la cygwin e scrivere:
cd voxforge (invio)
cd manual (invio)
perl ../HTK_scripts/prompts2mlf words.mlf prompts (invio)
L'esecuzione di prompts2mlf, creerà un file nella cartella manual, dal nome "words.mlf".
Tuttavia questo master label file, non è idoneo ai nostri scopi, perchè a Julius serve la corrispondenza sonora dei fonemi, non delle parole. Il file words.mlf, ha una struttura simile all'esempio che ho fatto prima e questo tipo di file, dato in pasto all'HTK, non assocerebbe i suoni fonetici alla relativa rappresentazione testuale dei nostri fonemi, ma renderebbe ogni singola parola specificata un solo fonema (un solo suono).
Il nostro obiettivo è partire da:
"sample1.lab"
CARLO
SCRIVE
..
E arrivare a:
"sample1.lab"
sil
k
a
r
l
o
sp
s
k
r
i
v
e
sp
..
Per non eseguire a mano questo impegnativo task, utilizziamo sempre l'HTK e il file che abbiamo creato prima, attraverso la compilazione del .grammar e del .voca, ovvero il il file che si trova nella cartella manual e che si chiama "dict".
All'interno della cartella manual creiamo un nuovo file e chiamiamolo mkphones0.led (mkphonesZERO). Dentro a mkphones0.led, scriviamo quello tra virgolette (senza le virgolette):
"EX
IS sil sil
DE sp"
Prima di chiudere e salvare, posizioniamo il cursore del mouse proprio dopo la parola sp e premiamo invio, in modo da lasciare un rigo vuoto sotto a quello che abbiamo scritto.
Salviamo mkphones0.led e lo chiudiamo.
Apriamo la cygwin e scriviamo:
cd voxforge (invio)
cd manual (invio)
dos2unix mkphones0.led (invio)
HLEd -A -D -T 1 -l '*' -d dict -i phones0.mlf mkphones0.led words.mlf (invio)
Il file mkphones0.led ci serve come file di configurazione per HLEd. Banalmente, diciamo ad HLEd, di creare un label file dalle parole contenute in words.mlf, ma queste parole devono essere divise in fonemi come specificato dal file dict. In fine, diciamo di scrivere il label file così ottenuto, dentro phones0.mlf.
Siamo a buon punto, infatti, dentro il file phones0.mlf, troviamo cose tipo:
"sample1.lab"
sil
k
a
r
l
o
s
k
r
i
v
e
...
sil
"sample2.lab"
sil
ci
i
a
o
k
o
m
e
v
a
...
Tuttavia, per le elaborazioni che dovremmo fare, ci serve un label file che abbia un fonema speciale, che serve per identificare la pausa di silenzio breve, che lo speaker fa tra l'esposizione di una parola e l'altra. Questo fonema particolare è "sp".
Dentro la cartella manual creiamo un nuovo file e chiamiamolo phones1.mlf. Dentro a phones1.mlf ci scriviamo quello che sta tra doppi apici, lasciando un rigo bianco alla fine del file (senza virgolette):
"EX
IS sil sil"
(ricordatevi di lasciare un rigo bianco alla fine, come avete fatto per mkphones0.led)
Salvate e chiudete il file.
Apriamo la cygwin e scriviamo:
cd voxforge (invio)
cd manual (invio)
dos2unix phones1.mlf (invio)
HLEd -A -D -T 1 -l '*' -d dict -i phones1.mlf mkphones1.led words.mlf (invio)
In questo caso, comandiamo ad HLEd, di utilizzare le informazioni fonetiche contenute nel dict, incrociandole con quelle testuali di words.mlf, per individuare ogni singola frase e metterci sil sia all'inizio che alla fine e per individuare ogni singola parola e metterci sp come separatore.
Abbiamo creato un label file utilizzabile per la costruzione del dizionario delle pronunce. Il nostro master label file è phones1.mlf, che trovate all'interno della cartella manual.
Abbiamo appena concluso lo step 4 del tutorial di voxforge che trovate qui:
www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/data-pre...
..Segue la manipolazione dei file sonori per poterli utilizzare nella stima del modello fonetico.. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 05/05/2013 15:27 | |
Per poter utilizzare gli esempi sonori che abbiamo registrato, dobbiamo trasformarli in un formato più conveniente, di veloce lettura e "comodo" per l'HTK.
Noi abbiamo registrato in formato wave, ma ci servono in formato mfcc (mel frequency cepstral coefficients), un formato veloce e opportuno per i nostri scopi.
Anche per questa operazione l'HTK ci aiuta con opportune funzioni di traduzione XD.
Apriamo risorse del computer, quindi C:, quindi cygwin, poi home, poi nomeUtente, poi voxforge, poi train.
Dentro la cartella train, crearne una nuova e chiamarla "mfcc".
Tornare in dietro fino alla cartella voxforge e aprire la cartella manual.
Dentro la cartella manual, creare un nuovo file e chiamarlo "codetrain.scp".
Il file codetrain.scp sarà un file di indirizzi che deve avere questa struttura:
(indirizzo di partenza file wave spazio indirizzo di destinazione file mfc)
../train/wav/sample1.wav ../train/mfcc/sample1.mfc
Per cui il nostro codetrain.scp, deve contenere all'interno tante righe quanti sono gli esempi sonori registrati.
ES:
Ho registrato 50 esempi sonori, da sample1.wav a sample50.wave, il mio codetrain.scp sarà:
../train/wav/sample1.wav ../train/mfcc/sample1.mfc
../train/wav/sample2.wav ../train/mfcc/sample2.mfc
../train/wav/sample3.wav ../train/mfcc/sample3.mfc
... ... ...
../train/wav/sample50.wav ../train/mfcc/sample50.mfc
Semplicemente copiate il rigo tra doppie virgolette (senza le doppie virgolette) dentro codetrain.scp, tante volte quanti esempi avete registrato:
"../train/wav/sample1.wav ../train/mfcc/sample1.mfc"
E dopo cambiate i due numeri "1" in numeri sempre crescenti, fino a coprire tutti gli esempi che avete registrato (e che sono contenuti nella cartella C:/cygwin/home/nomeUtente/voxforge/train/wav/).
Finita la scrittura di codetrain.scp, salvate e chiudete il file.
Andate nella cartella manual e create un nuovo file, chiamandolo "wav_config".
Dentro wav_config, scrivete il seguente testo tra virgolette (senza le virgolette):
"SOURCEFORMAT = WAV
TARGETKIND = MFCC_0_D
TARGETRATE = 100000.0
SAVECOMPRESSED = T
SAVEWITHCRC = T
WINDOWSIZE = 250000.0
USEHAMMING = T
PREEMCOEF = 0.97
NUMCHANS = 26
CEPLIFTER = 22
NUMCEPS = 12"
Salvate il file e chiudetelo.
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix codetrain.scp (invio)
dos2unix wav_config (invio)
HCopy -A -D -T 1 -C wav_config -S codetrain.scp (invio)
Aspettate che tutti gli esempi vengano processati prima di chiudere la cygwin!
Dovreste vedere una serie di scritte nella cygwin, che indicano che HCopy sta:
-leggendo rigo per rigo il vostro codetrain.scp;
-per ogni rigo capisce che deve prendere il file wave indicato nel primo indirizzo e trasformarlo in .mfc, salvandolo nel secondo indirizzo;
-ogni traduzione da .wav a .mfc, deve essere effettuata con i parametri stabiliti in wav_config.
Avete appena concluso lo step 5 del tutorial di voxforge che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/data-pre...
..Nel prossimo post, creeremo una struttura dati chiamata "modelli nascosti di Markov" (HMM), che associa ad ogni suono fonetico (la pronuncia di una lettera), la corrispondente rappresentazione testuale.. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 12/05/2013 16:27 | |
Premessa:
Virtualmente è possibile astrarre, attraverso regole matematiche (quindi numeri ed equazioni), comportamenti naturali (processi naturali), come la combustione, gli urti e anche il suono.
Naturalmente il suono viene percepito dal nostro orecchio, attraverso la capacità che ha il timpano, di piegarsi quando varia la pressione dell'aria.
Il timpano del computer, nel nostro caso, è il microfono.
Il microfono "sente" un suono, grazie alla variazione di pressione dell'aria che genera lo stesso suono.
Il nostro scopo è quello di "virtualizzare" quello che naturalmente succede nel nostro cervello quando il timpano sente una variazione di pressione dell'aria e quindi un suono.
Il nostro cervello, è infatti in grado, non solo di utilizzare i suoni che sente il timpano, ma anche di effettuare previsioni, nel caso in cui il timpano senta male.
Non potremmo mai dare a Julius la stessa intelligenza predittiva che ha il nostro cervello, ma qualcosina di lontanamente simile la possiamo ricreare grazie all'utilizzo della matematica statistica predittiva.
Il suono percepito dal microfono, come quello che percepisce l'orecchio umano, non è mai costituito da una sola componente..
ES:
Se io dico ad alta voce "ciao", il mio timpano non sentirà solo il suono che hanno generato le mie corde vocali, ma anche altri suoni, che non sono stati generati dalle mie corde vocali e che quindi per i nostri scopi, possono essere definiti rumori.
I rumori sono suoni non prevedibili a priori, perchè "aleatori".
Il Sig. Markov, si è inventato una procedura matematica che fa al caso nostro.
In maniera drasticamente semplificata, un modello nascosto di Markov, deve essere caricato con degli esempi (esempi di training) e dopo può essere utilizzato per ascoltare un suono (mischiato con rumore) e prevedere (azzardare, stimare), statisticamente, questo suono privo di rumore a quale lettera o parola corrisponde.
TUTORIAL:
Aprire risorse del computer, quindi C:, quindi cygwin, poi home, poi nomeUtente, poi voxforge, poi manual.
Dentro la cartella manual creare un nuovo file e chiamarlo proto.
Prima di creare modelli nascosti di Markov (HMM) descriventi parole, dobbiamo creare quelli che descrivo i fonemi.. E prima ancora di creare i HMM che descrivono fonemi, dobbiamo creare un "prototipo" di HMM. Creiamo il prototipo:
apriamo il file proto e copiamoci dentro quel che segue tra doppie virgolette (senza virgolette!E senza i trattini che trovate dopo il segno minore e prima del segno maggiore):
"~o <-VecSize-> 25 <-MFCC_0_D_N_Z->
~h "proto"
<-BeginHMM->
<-NumStates-> 5
<-State-> 2
<-Mean-> 25
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<-Variance-> 25
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<-State-> 3
<-Mean-> 25
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<-Variance-> 25
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<-State-> 4
<-Mean-> 25
0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0 0.0
<-Variance-> 25
1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0 1.0
<-TransP-> 5
0.0 1.0 0.0 0.0 0.0
0.0 0.6 0.4 0.0 0.0
0.0 0.0 0.6 0.4 0.0
0.0 0.0 0.0 0.7 0.3
0.0 0.0 0.0 0.0 0.0
<-EndHMM->"
Prima di salvare, posizionarsi, con il cursore del mouse, dopo <-EndHMM-> e lasciare un rigo.
Quindi salvare e chiudere il file.
Quello che noi abbiamo scritto non è altro che un HMM con 5 stati.
Creare un nuovo file dentro la cartella manual e chiamarlo config.
Copiare dentro al file appena creato il seguente testo tra doppie virgolette (senza le doppie virgolette):
"TARGETKIND = MFCC_0_D_N_Z
TARGETRATE = 100000.0
SAVECOMPRESSED = T
SAVEWITHCRC = T
WINDOWSIZE = 250000.0
USEHAMMING = T
PREEMCOEF = 0.97
NUMCHANS = 26
CEPLIFTER = 22
NUMCEPS = 12"
Sempre nella cartella manual, create una nuova cartella e chiamatela hmm0.
Ancora in manual, create un nuovo file e chiamatelo train.scp.
Il file train.scp, è simile al file codetrain.scp, ma deve contenere un solo indirizzo. Dobbiamo infatti dare all'HTK, gli indirizzi dei file .mfc che abbiamo creato nello step precedente!
Dentro al file train.scp, va scritto qualcosa del tipo:
"../train/mfcc/sample1.mfc
../train/mfcc/sample2.mfc
../train/mfcc/sample3.mfc
...
...
../train/mfcc/sampleULTIMONUMERO.mfc"
Per ogni file sonoro, abbiamo il corrispondente mfc dentro la cartella mfcc. Per ciascun file contenuto nella cartella C:/cygwin/home/nomeUtente/voxforge/train/mfcc/ dobbiamo avere un rigo dentro al file train.scp.
Se avessimo voluto registrare 10 sample, avendo chiamato il primo "sample1", allora dentro il nostro train.scp, avremmo dovuto scrivere:
"../train/mfcc/sample1.mfc
../train/mfcc/sample2.mfc
../train/mfcc/sample3.mfc
../train/mfcc/sample4.mfc
../train/mfcc/sample5.mfc
../train/mfcc/sample6.mfc
../train/mfcc/sample7.mfc
../train/mfcc/sample8.mfc
../train/mfcc/sample9.mfc
../train/mfcc/sample10.mfc"
Aprire la cygwin e scrivere:
cd voxforge (invio)
cd manual (invio)
dos2unix proto (invio)
dos2unix config (invio)
dos2unix train.scp (invio)
HCompV -A -D -T 1 -C config -f 0.01 -m -S train.scp -M hmm0 proto (invio)
L'esecuzione dei comandi di sopra creerà il nostro primo HMM dentro la cartella hmm0. Aprite la cartella hmm0 e controllate che all'interno ci siano i file:
- proto
- vFloors
Ci sono??
Si, ottimo!
Si, ma sono file vuoti, oppure non ci sono... Riscrivete sulla cygwin:
HCompV -A -D -T 1 -C config -f 0.01 -m -S train.scp -M hmm0 proto (invio)
Segnatevi il messaggio che vi scrive HCompV e chiedete qui in forum, avete fatto qualche errore! O ricominciate d'accapo, oppure mi fate vedere l'errore che vi dà HCompV e magari potete risparmiarvi qualche sbattimento..
Entrate nella cartella manual e copiate il file monophones0.
Per copiare un file, basta cliccare sul nome del file con il pulsante destro del mouse e selezionare "copia".
Aprire la cartella hmm0 e incollare il file appena copiato.
Per incollare un file che precedentemente è stato copiato, basta cliccare con il pulsante destro del mouse all'interno di una cartella e selezionare "incolla".
Dopo aver incollato il file monophones0 dentro la cartella hmm0, questo nuovo file, si chiamerà monophones0.
Quindi dentro la cartella hmm0 vi trovate 3 file:
- vFloors
- proto
- monophones0
Rinominate il file monophones0, con il nuovo nome "hmmdefs".
Aprite il file hmmdefs, dentro trovate, per ogni rigo, un fonema del vostro modello.
Prima di ogni fonema scrivere "~h" (senza le virgolette) e lasciate uno spazio, poi mettete tra doppi apici il fonema che trovate.
ES
hmmdefs prima:
a
b
ci
..
hmmdefs dopo:
~h "a"
~h "b"
~h "ci"
..
Non chiudete il file hmmdefs.
Aprite il file dal nome proto, che è contenuto nella cartella hmm0.
All'interno del file proto, copiate il testo contenuto da <-BEGINHMM-> fino a <-ENDHMM-> (ricordatevi che i trattini dopo il segno minore e maggiore, li scrivo solo perchè altrimenti ffz non mi fa visualizzare la parola, ma non ci sono, nè vanno aggiunti!), copiando anche le due parole chiave menzionate.
Chiudete il file proto e tornate sul file hmmdefs.
Posizionate il cursore del mouse dopo il primo fonema tra virgolette (a destra dell'ultima virgoletta), premete invio e incollate nel rigo di sotto quello che prima avevate copiato dal file proto.
ES:
hmmdefs prima:
~h "a"
~h "b"
~h "ci"
..
hmmdefs dopo (i trattini non vanno scritti!):
~h "a"
<-BEGINHMM->
..
<-ENDHMM->
~h "b"
<-BEGINHMM->
..
<-ENDHMM->
~h "ci"
<-BEGINHMM->
..
<-ENDHMM->
..
Non avete bisogno di copiare ogni volta la porzione di codice che vi interessa e contenuta in proto. Basta copiarla una sola volta per essere incollata tutte le volte che volete.
Dopo aver finito questa operazione, posizionate il cursore del mouse alla fine del file hmmdefs, proprio dopo la parola chiave <-ENDHMM-> e premete invio, in modo da lasciare un rigo bianco alla fine del file.
Salvate il file e chiudetelo.
Create un nuovo file dentro hmm0 e chiamatelo macros.
Aprite il file vFloors che avete dentro la vostra cartella hmm0 e copiatene l'intero contenuto.
Chiudete il file vFloors.
Aprite il file macros e incollateci dentro quello che avete copiato.
Lasciate aperto il file macros e aprite anche il file proto.
Da dentro proto copiate il frammento di testo che va da "~o" a "<-DIAGC->", copiando anche le parole chiave menzionate (sono i primi 5 righi di proto!).
Chiudete il file proto.
Tornate al file macros e incollate quel che avete copiato dal file proto all'inizio del file macros.
ES:
macros prima (i trattini non ci sono,servono solo per far visualizzare la parola chiave!):
~v varFloor1
<-Variance-> 25
....
macros dopo:
~o
<-STREAMINFO-> 1 25
<-VECSIZE-> 25<-NULLD-><-MFCC_D_N_Z_0-><-DIAGC->
~v varFloor1
<-Variance-> 25
....
Salvate il file macros e chiudetelo.
Create nella cartella manual altre 9 cartelle:
- hmm1
- hmm2
- hmm3
- hmm4
- hmm5
- hmm6
- hmm7
- hmm8
- hmm9
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
cd hmm0 (invio)
dos2unix macros (invio)
dos2unix hmmdefs (invio)
cd .. (invio)
HERest -A -D -T 1 -C config -I phones0.mlf -t 250.0 150.0 1000.0 -S train.scp -H hmm0/macros -H hmm0/hmmdefs -M hmm1 monophones0 (invio)
HERest -A -D -T 1 -C config -I phones0.mlf -t 250.0 150.0 1000.0 -S train.scp -H hmm1/macros -H hmm1/hmmdefs -M hmm2 monophones0 (invio)
HERest -A -D -T 1 -C config -I phones0.mlf -t 250.0 150.0 1000.0 -S train.scp -H hmm2/macros -H hmm2/hmmdefs -M hmm3 monophones0 (invio)
La funzione HERest la prima volta che viene eseguita ci metterà un pò di tempo ad effettuare la sua elaborazione, dipende da quanti esempi di training avete registrato!
Se avete effettuato errori, vi bloccherete alla prima esecuzione di HERest e le altre non andranno a buon fine (leggerete FATAL ERROR).
Vi invito, anche per HERest, a segnarvi l'errore e domandare qui in forum, da cosa potrebbe derivare l'errore.
La prima volta che ho costruito un modello acustico, proprio a questo punto, sono rimasto bloccato per più di 10 gironi a causa di FATAL ERROR che mi dava la prima HERest.. Per poi capire (studiando l'HTK book), che sul sito di voxforge la I (i stampatello) sembra una l (l minuscola).
Avete appena concluso lo step 6 del tutorial voxforge per windows, che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/monophone...
..Nel prossimo post considereremo anche il silenzio tra parole e lo andremo ad inserire nei nostri HMM, in modo da poter dare la capacità al nostro modello acustico, di distinguere le parole, semplicemente confrontando due pause di silenzio.. [Modificato da calel82 12/05/2013 16:33] |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 27/05/2013 15:05 | |
Inserimento del modello silenzio all'interno dei nostri HMMs.
Subito al lavoro!
Apriamo risorse del computer, poi C:, poi cygwin, poi home, poi nomeUtente, poi voxforge, poi manual, poi hmm3.
Dentro hmm3 troverete 2 file, copiateli.
Tornate indietro nella cartella manual e aprite la cartella hmm4.
Incollate dentro la cartella hmm4 (che troverete vuota), i file che precedentemente avete copiato.
Dopo aver incollato hmmdefs e macro, aprite il file hmmdefs.
Quello che vedete è la definizione dei modelli nascosti per ogni fonema che avete creato.
Ogni definizione di modello nascosto ha questa struttura (vi ricordo che i trattini non ci sono in quel che leggete, ma li devo scrivere, altrimenti non viene visualizzato correttamente il contenuto testuale che vi espongo..):
~h "a" (che è il nome del fonema)
<-BEGINHMM-> (indica che seguono i dati che interessano all'HTK)
<-NUMSTATES-> 5
<-STATE-> 2
<-MEAN-> 25
-5.906928e+00 1.628486e-01 -3.625001e+00 -2.614522e-01 -5.282461e-01 2.667645e+00 5.102982e+00 1.545549e+00 3.636499e+00 3.845983e+00 1.652724e+00 3.094676e+00 -1.280174e-02 4.684002e-03 -6.184035e-03 2.562511e-03 -1.723273e-02 -1.433755e-02 -1.419702e-03 6.881847e-03 8.888377e-03 1.908680e-02 -1.435490e-03 -1.790903e-03 -1.929774e-02
<-VARIANCE-> 25
2.578038e+00 4.442047e+00 4.140977e+00 7.220293e+00 5.614420e+00 6.987432e+00 6.700070e+00 7.252159e+00 7.256308e+00 7.189629e+00 6.118056e+00 6.151144e+00 8.845596e-02 1.685021e-01 2.721096e-01 3.408231e-01 4.153289e-01 6.151640e-01 6.025191e-01 5.456595e-01 6.351454e-01 6.605052e-01 6.318872e-01 5.852073e-01 4.117725e-02
<-GCONST-> 5.280386e+01
<-STATE-> 3
<-MEAN-> 25
-7.046570e+00 -3.262981e-01 -1.706483e+00 -1.080971e+00 -1.134529e+00 3.588506e+00 3.917166e+00 1.443405e+00 4.899211e+00 3.409961e+00 8.219168e-01 3.644213e+00 -7.641904e-02 -6.077167e-02 2.118241e-01 -8.631640e-02 3.686112e-02 8.506200e-02 -8.106526e-02 1.066912e-02 1.281262e-01 -1.437282e-01 -3.412217e-02 1.333326e-01 1.202221e-01
<-VARIANCE-> 25
7.911258e+00 8.348815e+00 1.148870e+01 1.213321e+01 8.655976e+00 1.509970e+01 9.904381e+00 1.166922e+01 1.025182e+01 8.845907e+00 8.135198e+00 9.622693e+00 9.084668e-01 7.631339e-01 1.614822e+00 9.755048e-01 7.167343e-01 1.691362e+00 1.297928e+00 9.801642e-01 1.225108e+00 1.051384e+00 9.349809e-01 1.529028e+00 5.576642e-01
<-GCONST-> 7.411308e+01
<-STATE-> 4
<-MEAN-> 25
1.987629e+00 8.999189e-01 3.864730e-01 -4.687709e-01 5.336301e-01 2.345200e-01 -8.621325e-01 1.230609e-01 -9.877484e-01 -1.324250e+00 1.351032e-01 -5.023057e-01 -1.919302e-02 -2.812544e-02 8.604265e-02 -5.349477e-02 5.288856e-03 2.348321e-02 -4.238142e-02 -1.502599e-02 1.916558e-02 -7.591232e-02 -1.932539e-02 5.544404e-02 7.039443e-02
<-VARIANCE-> 25
7.070191e+01 2.758622e+01 4.226409e+01 5.562771e+01 4.209383e+01 4.503211e+01 5.569194e+01 2.290340e+01 4.379171e+01 3.098044e+01 2.271026e+01 3.398006e+01 1.596598e+00 1.241183e+00 1.819241e+00 1.869536e+00 1.712559e+00 2.155400e+00 2.495838e+00 1.685049e+00 2.046765e+00 1.598639e+00 1.526519e+00 1.757828e+00 1.175106e+00
<-GCONST-> 9.682940e+01
<-TRANSP-> 5
0.000000e+00 1.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
0.000000e+00 9.641963e-01 3.580364e-02 0.000000e+00 0.000000e+00
0.000000e+00 0.000000e+00 8.946286e-01 1.053714e-01 0.000000e+00
0.000000e+00 0.000000e+00 0.000000e+00 9.613560e-01 3.864404e-02
0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
<-ENDHMM-> (indica la fine del modello nascosto)
Cercate all'interno del file la parola sil, dovreste trovarla quasi alla fine del file. In pratica dovete cercare il modello nascosto che esprime il fonema "sil", ovvero qualcosa del genere:
~h "sil" (che è il nome del fonema che dovete trovare)
<-BEGINHMM-> (indica che seguono i dati che interessano all'HTK)
<-NUMSTATES-> 5
<-STATE-> 2
<-MEAN-> 25
-5.906928e+00 1.628486e-01 -3.625001e+00 -2.614522e-01 -5.282461e-01 2.667645e+00 5.102982e+00 1.545549e+00 3.636499e+00 3.845983e+00 1.652724e+00 3.094676e+00 -1.280174e-02 4.684002e-03 -6.184035e-03 2.562511e-03 -1.723273e-02 -1.433755e-02 -1.419702e-03 6.881847e-03 8.888377e-03 1.908680e-02 -1.435490e-03 -1.790903e-03 -1.929774e-02
<-VARIANCE-> 25
2.578038e+00 4.442047e+00 4.140977e+00 7.220293e+00 5.614420e+00 6.987432e+00 6.700070e+00 7.252159e+00 7.256308e+00 7.189629e+00 6.118056e+00 6.151144e+00 8.845596e-02 1.685021e-01 2.721096e-01 3.408231e-01 4.153289e-01 6.151640e-01 6.025191e-01 5.456595e-01 6.351454e-01 6.605052e-01 6.318872e-01 5.852073e-01 4.117725e-02
<-GCONST-> 5.280386e+01
<-STATE-> 3
<-MEAN-> 25
-7.046570e+00 -3.262981e-01 -1.706483e+00 -1.080971e+00 -1.134529e+00 3.588506e+00 3.917166e+00 1.443405e+00 4.899211e+00 3.409961e+00 8.219168e-01 3.644213e+00 -7.641904e-02 -6.077167e-02 2.118241e-01 -8.631640e-02 3.686112e-02 8.506200e-02 -8.106526e-02 1.066912e-02 1.281262e-01 -1.437282e-01 -3.412217e-02 1.333326e-01 1.202221e-01
<-VARIANCE-> 25
7.911258e+00 8.348815e+00 1.148870e+01 1.213321e+01 8.655976e+00 1.509970e+01 9.904381e+00 1.166922e+01 1.025182e+01 8.845907e+00 8.135198e+00 9.622693e+00 9.084668e-01 7.631339e-01 1.614822e+00 9.755048e-01 7.167343e-01 1.691362e+00 1.297928e+00 9.801642e-01 1.225108e+00 1.051384e+00 9.349809e-01 1.529028e+00 5.576642e-01
<-GCONST-> 7.411308e+01
<-STATE-> 4
<-MEAN-> 25
1.987629e+00 8.999189e-01 3.864730e-01 -4.687709e-01 5.336301e-01 2.345200e-01 -8.621325e-01 1.230609e-01 -9.877484e-01 -1.324250e+00 1.351032e-01 -5.023057e-01 -1.919302e-02 -2.812544e-02 8.604265e-02 -5.349477e-02 5.288856e-03 2.348321e-02 -4.238142e-02 -1.502599e-02 1.916558e-02 -7.591232e-02 -1.932539e-02 5.544404e-02 7.039443e-02
<-VARIANCE-> 25
7.070191e+01 2.758622e+01 4.226409e+01 5.562771e+01 4.209383e+01 4.503211e+01 5.569194e+01 2.290340e+01 4.379171e+01 3.098044e+01 2.271026e+01 3.398006e+01 1.596598e+00 1.241183e+00 1.819241e+00 1.869536e+00 1.712559e+00 2.155400e+00 2.495838e+00 1.685049e+00 2.046765e+00 1.598639e+00 1.526519e+00 1.757828e+00 1.175106e+00
<-GCONST-> 9.682940e+01
<-TRANSP-> 5
0.000000e+00 1.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
0.000000e+00 9.641963e-01 3.580364e-02 0.000000e+00 0.000000e+00
0.000000e+00 0.000000e+00 8.946286e-01 1.053714e-01 0.000000e+00
0.000000e+00 0.000000e+00 0.000000e+00 9.613560e-01 3.864404e-02
0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00 0.000000e+00
<-ENDHMM-> (indica la fine del modello nascosto)
Dopo averlo trovato, copiate l'intero contenuto del modello nascosto, da ~h "sil", fino a <-ENDHMM-> (copiate, non tagliate, mi raccomando!)
Posizionatevi alla fine del file, quindi dopo <-ENDHMM-> (posizionado il cursore alla destra del simbolo maggiore ">") e premete invio.
Quindi incollate sul nuovo rigo che avete appena scritto il modello sil che avete copiato prima.
Nella copia del modello sil dovete fare le seguenti modifiche:
1- posizionatevi dove sta scritto ~h "sil" e modificatelo scrivendo ~h "sp";
2- cancellate da "<-STATE-> 2" (<-STATE-> 2 compreso) fino a "<-GCONST->" (dopo <-GCONST-> vedrete un numero, va cancellato anche quello!);
3- Cambiate il numero che sta dopo "<-NUMSTATES->" in 2;
4- Cambiate il numero che sta dopo "<-STATE->" in 2;
5- Cambiate il numero che sta dopo "<-TRANSP->" in 3;
6- Cancellate i numeri che stanno tra <-TRANSP-> e <-ENDHMM->, in modo da vedere scritto qualcosa del genere:
~h "sp"
<-BEGINHMM->
<-NUMSTATES-> 3
<-STATE-> 2
<-MEAN-> 25
-7.046570e+00 -3.262981e-01 -1.706483e+00 -1.080971e+00 -1.134529e+00 3.588506e+00 3.917166e+00 1.443405e+00 4.899211e+00 3.409961e+00 8.219168e-01 3.644213e+00 -7.641904e-02 -6.077167e-02 2.118241e-01 -8.631640e-02 3.686112e-02 8.506200e-02 -8.106526e-02 1.066912e-02 1.281262e-01 -1.437282e-01 -3.412217e-02 1.333326e-01 1.202221e-01
<-VARIANCE-> 25
7.911258e+00 8.348815e+00 1.148870e+01 1.213321e+01 8.655976e+00 1.509970e+01 9.904381e+00 1.166922e+01 1.025182e+01 8.845907e+00 8.135198e+00 9.622693e+00 9.084668e-01 7.631339e-01 1.614822e+00 9.755048e-01 7.167343e-01 1.691362e+00 1.297928e+00 9.801642e-01 1.225108e+00 1.051384e+00 9.349809e-01 1.529028e+00 5.576642e-01
<-GCONST-> 7.411308e+01
<-TRANSP-> 3
<-ENDHMM->
Non vi resta che posizionare il cursore del mouse dopo il <-TRANSP-> 3 (dopo il 3) e premere invio, in modo da vedere questo:
<-TRANSP-> 3
<-ENDHMM->
Copiate quello che segue tra doppi apici (senza copiare i doppi apici)
" 0.0 1.0 0.0
0.0 0.9 0.1
0.0 0.0 0.0"
Tornate sul file hmmdefs e incollate i numeri nel rigo bianco tra <-TRANSP-> e <-ENDHMM->, in modo da ottenere questo che segue:
<-TRANSP-> 3
0.0 1.0 0.0
0.0 0.9 0.1
0.0 0.0 0.0
<-ENDHMM->
Alla fine, il vostro modello sp, dovrebbe essere tipo questo (differendo ovviamente dai numeri decimali, che di sicuro saranno diversi):
~h "sp"
<-BEGINHMM->
<-NUMSTATES-> 3
<-STATE-> 2
<-MEAN-> 25
-7.046570e+00 -3.262981e-01 -1.706483e+00 -1.080971e+00 -1.134529e+00 3.588506e+00 3.917166e+00 1.443405e+00 4.899211e+00 3.409961e+00 8.219168e-01 3.644213e+00 -7.641904e-02 -6.077167e-02 2.118241e-01 -8.631640e-02 3.686112e-02 8.506200e-02 -8.106526e-02 1.066912e-02 1.281262e-01 -1.437282e-01 -3.412217e-02 1.333326e-01 1.202221e-01
<-VARIANCE-> 25
7.911258e+00 8.348815e+00 1.148870e+01 1.213321e+01 8.655976e+00 1.509970e+01 9.904381e+00 1.166922e+01 1.025182e+01 8.845907e+00 8.135198e+00 9.622693e+00 9.084668e-01 7.631339e-01 1.614822e+00 9.755048e-01 7.167343e-01 1.691362e+00 1.297928e+00 9.801642e-01 1.225108e+00 1.051384e+00 9.349809e-01 1.529028e+00 5.576642e-01
<-GCONST-> 7.411308e+01
<-TRANSP-> 3
0.0 1.0 0.0
0.0 0.9 0.1
0.0 0.0 0.0
<-ENDHMM->
Salvate il file e chiudetelo.
Tornate nella cartella manual e create un nuovo file, dal nome sil.hed.
Dentro a sil.hed, incollateci il seguente testo contenuto tra doppi apici (senza copiare i doppi apici):
"AT 2 4 0.2 {sil.transP}
AT 4 2 0.2 {sil.transP}
AT 1 3 0.3 {sp.transP}
TI silst {sil.state[3],sp.state[2]}"
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
cd hmm4 (invio)
dos2unix hmmdefs (invio)
cd .. (invio)
dos2unix sil.hed (invio)
HHEd -A -D -T 1 -H hmm4/macros -H hmm4/hmmdefs -M hmm5 sil.hed monophones1 (invio)
Non chiudete la cygwin!
L'elaborazione potrebbe richiedere alcuni minuti, aspettate che finisca e controllate bene che non ci sia scritto FATAL ERROR nell'ultima riga che vi viene stampata a video.
Se leggete FATAL ERROR, bhè avete 3 cose possibili da fare:
1- Mettete a repentaglio la vostra sanità mentale studiandovi l'HTK;
2- Rifate tutto il procedimento d'accapo;
3- Vi segnate il messaggio di errore (vedrete anche un numerino) e chiedete su questo forum cosa fare..
Finita l'elaborazione di HHEd, scrivete sulla cygwin:
HERest -A -D -T 1 -C config -I phones1.mlf -t 250.0 150.0 3000.0 -S train.scp -H hmm5/macros -H hmm5/hmmdefs -M hmm6 monophones1 (invio)
Anche qui c'è da aspettare e pregate che non vi dia errori!
Dopo che HERest ha finito scrivete (sempre nella cygwin):
HERest -A -D -T 1 -C config -I phones1.mlf -t 250.0 150.0 3000.0 -S train.scp -H hmm6/macros -H hmm6/hmmdefs -M hmm7 monophones1 (invio)
Stessa storia, un pò di pazienza, c'è da aspettare l'elaborazione.
Avete appena concluso lo Step 7 del tutorial voxforge che trovate qui:
www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/monophone...
Ora avete fissato il modello "piccola pausa di silenzio" e potete costruire modelli nascosti idonei per il riconoscimento vocale!
Fin ora abbiamo giocato, ora comincia il vero divertimento!
Nel prossimo post effettueremo una particolare elaborazione dei nostri dati di training, atta a uniformare la pronuncia aperta e/o chiusa di alcuni suoni (come le vocali).. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 21/06/2013 13:43 | |
Allineamento fonetico e nuova stima dei modelli nascosti di Markov.
In italiano, come in altri linguaggi, alcuni fonemi, vengono pronunciati in maniera diversa a seconda del contesto grammaticale.
In realtà avremmo potuto pensare una costruzione fonetica che prevedeva queste discordanze, ma questo avrebbe portato la conseguente crescita dei dati di training (ogni fonema, deve avere un "addestramento" minimo per essere opportunamente riconosciuto).
Cominciamo ad allineare tutti i suoni legati ad ogni fonema in maniera opportuna!
Apriamo la cygwin, e scriviamo:
cd voxforge (invio)
cd manual (invio)
HVite -A -D -T 1 -l '*' -o SWT -b SENT-END -C config -H hmm7/macros -H hmm7/hmmdefs -i aligned.mlf -m -t 250.0 150.0 1000.0 -y lab -a -I words.mlf -S train.scp dict monophones1> HVite_log (invio)
Non chiudete la cygwin.
Se HVite esegue sena errori non verrà visualizzato nessun messaggio, altrimenti, i possibili errori potrebbero essere la conseguenza di una dimenticanza o una distrazione nel file wlist (il 20% delle volte ci si dimentica di scrivere le parole chiave SENT-END oppure SENT-START e HVite si impalla).
HVite creerà il file aligned.mlf e un file di diagnostica: "HVite_log".
Sarebbe opportuno controllare il file HVite_log, per essere sicuri che HVite abbia effettuato bene l'elaborazione.
In realtà non c'è necessità di farlo se abbiamo un training piccolino (meno di 1000 esempi), saranno le ulteriori operazioni a farci scoprire eventuali fallimenti di HVite..
Scriviamo sulla cygwin:
HERest -A -D -T 1 -C config -I aligned.mlf -t 250.0 150.0 3000.0 -S train.scp -H hmm7/macros -H hmm7/hmmdefs -M hmm8 monophones1 (invio)
HERest leggerà tutto il file aligned.mlf e lo utilizzerà come "guida" per utilizzare tutto il training effettuato.
Per ogni esempio di training, HERest vi presenterà una risposta sulla cygwin.
Se HVite non ha funzionato bene, l'esecuzione di HERest si arresterà, dandovi un FATAL ERROR e scrivendovi che non trova una "label".
In tal caso conviene tornare all'inizio di questo post e rieseguire HVite, anche se questo NON vi assicura che non avrete nuovamente gli stessi errori o altri. Nel caso, dopo diversi tentativi, continuate ad avere errori di "label", copiate il messaggio di errore e chiedete qui, vi aiuterò a risolvere l'errore.
Scrivete sopra la cygwin:
HERest -A -D -T 1 -C config -I aligned.mlf -t 250.0 150.0 3000.0 -S train.scp -H hmm7/macros -H hmm7/hmmdefs -M hmm8 monophones1 (invio)
Vi basta che la prima esecuzione di HERest vada a buon fine, che tutte le altre non vi daranno errori..
Aspettate che HERest finisca e continuate a scrivere sulla cygwin:
HERest -A -D -T 1 -C config -I aligned.mlf -t 250.0 150.0 3000.0 -S train.scp -H hmm8/macros -H hmm8/hmmdefs -M hmm9 monophones1 (invio)
Queste chiamate ad HERest, vi creeranno:
- Nella cartella hmm8, i file: hmmdefs e macros;
- Nella cartella hmm9, i file: hmmdefs e macros.
I modelli nascosti appena creati possono essere già utilizzati da Julius, ma il risultato sarebbe pessimo..
In effetti noi abbiamo creato modelli nascosti che riconoscono singoli fonemi, ovvero che fanno previsioni su singoli fonemi, cosa che sarebbe -teoricamente- ottima per l'italiano, ma che -in pratica- Julius non è capace di gestire in maniera opportuna (e fin ora nessun engine STT riesce a farlo..)!
Avete appena concluso lo step 8 del tutorial voxforge, che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/monophone...
Nel prossimo post, costruiremo HMM che considerano triplici fonemi, ovvero 3 suoni alla volta.. Così facendo potremmo utilizzare al meglio l'engine STT Julius. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 21/06/2013 14:47 | |
Costruzione dei triplici fonemi.
Subito a lavoro!
Aprite risorse del computer, poi cygwin, poi home, poi nomeUtente, poi voxforge, poi manual.
Create un nuovo file nella cartella manual e chiamatelo "mktri.led".
Dentro a mktri.led, scrivete quello tra doppi apici (senza copiare i doppi apici!):
"WB sp
WB sil
TC"
Dopo aver copiato il contenuto dentro mktri.led, ricordatevi di aggiungere un rigo vuoto alla fine, ovvero:
posizionate il cursore del mouse a destra di "TC" e premete invio.
Salvate mktri.led e chiudete il file.
Sempre dentro la cartella "manual", create altre 3 cartelle:
-hmm10
-hmm11
-hmm12
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix mktri.led (invio)
HLEd -A -D -T 1 -n triphones1 -l '*' -i wintri.mlf mktri.led aligned.mlf (invio)
Aspettate che termina l'esecuzione e continuate a scrivere sulla cygwin:
perl ../HTK_scripts/maketrihed monophones1 triphones1 (invio)
Sempre dopo che termina l'esecuzione, continuate a scrivere (e attendete la fine dell'esecuzione dopo agni invio..):
HHEd -A -D -T 1 -H hmm9/macros -H hmm9/hmmdefs -M hmm10 mktri.hed monophones1 (invio)
HERest -A -D -T 1 -C config -I wintri.mlf -t 250.0 150.0 3000.0 -S train.scp -H hmm10/macros -H hmm10/hmmdefs -M hmm11 triphones1 (invio)
HERest -A -D -T 1 -C config -I wintri.mlf -t 250.0 150.0 3000.0 -s stats -S train.scp -H hmm11/macros -H hmm11/hmmdefs -M hmm12 triphones1 (invio)
Queste operazioni creeranno (se non avete fatto errori) i seguenti file:
- nella cartella manual: wintri.mlf, triphones1 e mktri.hed;
- nella cartella hmm10: hmmdefs e macros;
- nella cartella hmm11: hmmdefs e macros.
- nella cartella hmm12: hmmdefs e macros.
Avete appena concluso lo step 9 del tutorial voxforge, che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/triphone...
Nel prossimo post creeremo l'albero decisionale, che Julius utilizzerà per effettuare il riconoscimento vocale. ![[SM=g27988]](https://im0.freeforumzone.it/up/0/88/16680848.gif) |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 21/06/2013 15:31 | |
A questo punto dobbiamo creare un albero decisionale, che possa aiutare Julius a riconoscere le parole che noi diciamo a microfono.
Questo albero, verrà navigato attraverso fonemi e sarà indispensabile a Julius per stabilire quale parola, contenuta nel modello acustico, più si avvicina a quella che lui ha sentito.
Apriamo risorse del computer, poi cygwin, poi home, poi nomeUtente, poi voxforge, poi manual.
Dentro la cartella manual, creiamo un nuovo file e chiamiamolo "global.ded".
Dentro al file global.ded, scriviamo quello che segue tra doppi apici (senza copiare i doppi apici!):
"AS sp
RS cmu
MP sil sil sp"
Non c'è bisogno di lasciare il rigo vuoto alla fine..
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix global.ded (invio)
HDMan -A -D -T 1 -b sp -n fulllist -g global.ded -l flog dict-tri ../lexicon/voxforge_lexicon (invio)
Non chiudete la cygwin.
Questo creerà nella cartella manual, due nuovi file: dict-tri e fulllist.
Dentro la cartella manual, create un nuovo file e chiamatelo "fulllist1".
Aprite il file fulllist1 appena creato e lasciatelo aperto.
Aprite il file fulllist e copiatene l'intero contenuto, incollandolo dentro il file fulllist1. Chiudete il file fulllist e aprite il file triphones1.
Copiate l'intero contenuto del file triphones1 e chiudetelo.
Ponete la vostra attenzione sul file fullist1 e posizionate il cursore del mouse alla fine di quello che vi avete incollato dentro, state attenti a posizionare bene il cursore, in modo che sia esattamente alla fine di tutto quello che sta scritto, premete invio e incollate quello che avevate selezionato da triphones1, esattamente nel rigo vuoto che avete alla fine del file.
In pratica fulllist1 deve essere così costruito:
- contenuto di fullist + premi pulsante invio per andare a nuovo rigo;
- contenuto di triphones1.
Salvate fulllist1 e chiudetelo.
Create un nuovo file nella cartella manual e chiamatelo fixfulllist.pl.
Dentro il file fixfulllist.pl scrivete quel che segue tra doppi apici (senza copiare i doppi apici):
"#!/usr/bin/perl
use strict;
my ($line, $label, $filein, $fileout, %seen);
if (@ARGV != 2) {
print "usage: $0 filein fileout\n\n";
exit (0);
}
# read in command line arguments
($filein, $fileout) = @ARGV;
open (FILEIN,"$filein") || die ("Unable to open $filein for reading");
open (FILEOUT,">$fileout") || die ("Unable to open $fileout for writing");
%seen = ();
while ($line = ) {
chomp ($line);
unless ($seen{$line}) { # remove duplicate triphone names
$seen{$line} = 1;
print (FILEOUT "$line\n");
}
}
close(FILEOUT);"
Salvate il file fixfulllist.pl e chiudetelo.
Scrivete sulla cygwin:
dos2unix fulllist1 (invio)
dos2unix fixfulllist.pl (invio)
perl fixfulllist.pl fulllist1 fulllist (invio)
Non chiudete la cygwin.
Create un nuovo file nella vostra cartella manual e chiamatelo tree.hed.
Dentro a questo file incollate quel che segue tra doppi apici (senza copiare i doppi apici):
"RO 100 stats
TR 0
QS "R_NonBoundary" { *+* }
QS "R_Silence" { *+sil }
QS "R_Stop" { *+p,*+pd,*+b,*+t,*+td,*+d,*+dd,*+k,*+kd,*+g }
QS "R_Nasal" { *+m,*+n,*+en,*+ng }
QS "R_Fricative" { *+s,*+sh,*+z,*+f,*+v,*+ch,*+jh,*+th,*+dh }
QS "R_Liquid" { *+l,*+el,*+r,*+w,*+y,*+hh }
QS "R_Vowel" { *+eh,*+ih,*+ao,*+aa,*+uw,*+ah,*+ax,*+er,*+ay,*+oy,*+ey,*+iy,*+ow }
QS "R_C-Front" { *+p,*+pd,*+b,*+m,*+f,*+v,*+w }
QS "R_C-Central" { *+t,*+td,*+d,*+dd,*+en,*+n,*+s,*+z,*+sh,*+th,*+dh,*+l,*+el,*+r }
QS "R_C-Back" { *+sh,*+ch,*+jh,*+y,*+k,*+kd,*+g,*+ng,*+hh }
QS "R_V-Front" { *+iy,*+ih,*+eh }
QS "R_V-Central" { *+eh,*+aa,*+er,*+ao }
QS "R_V-Back" { *+uw,*+aa,*+ax,*+uh }
QS "R_Front" { *+p,*+pd,*+b,*+m,*+f,*+v,*+w,*+iy,*+ih,*+eh }
QS "R_Central" { *+t,*+td,*+d,*+dd,*+en,*+n,*+s,*+z,*+sh,*+th,*+dh,*+l,*+el,*+r,*+eh,*+aa,*+er,*+ao }
QS "R_Back" { *+sh,*+ch,*+jh,*+y,*+k,*+kd,*+g,*+ng,*+hh,*+aa,*+uw,*+ax,*+uh }
QS "R_Fortis" { *+p,*+pd,*+t,*+td,*+k,*+kd,*+f,*+th,*+s,*+sh,*+ch }
QS "R_Lenis" { *+b,*+d,*+dd,*+g,*+v,*+dh,*+z,*+sh,*+jh }
QS "R_UnFortLenis" { *+m,*+n,*+en,*+ng,*+hh,*+l,*+el,*+r,*+y,*+w }
QS "R_Coronal" { *+t,*+td,*+d,*+dd,*+n,*+en,*+th,*+dh,*+s,*+z,*+sh,*+ch,*+jh,*+l,*+el,*+r }
QS "R_NonCoronal" { *+p,*+pd,*+b,*+m,*+k,*+kd,*+g,*+ng,*+f,*+v,*+hh,*+y,*+w }
QS "R_Anterior" { *+p,*+pd,*+b,*+m,*+t,*+td,*+d,*+dd,*+n,*+en,*+f,*+v,*+th,*+dh,*+s,*+z,*+l,*+el,*+w }
QS "R_NonAnterior" { *+k,*+kd,*+g,*+ng,*+sh,*+hh,*+ch,*+jh,*+r,*+y }
QS "R_Continuent" { *+m,*+n,*+en,*+ng,*+f,*+v,*+th,*+dh,*+s,*+z,*+sh,*+hh,*+l,*+el,*+r,*+y,*+w }
QS "R_NonContinuent" { *+p,*+pd,*+b,*+t,*+td,*+d,*+dd,*+k,*+kd,*+g,*+ch,*+jh }
QS "R_Strident" { *+s,*+z,*+sh,*+ch,*+jh }
QS "R_NonStrident" { *+f,*+v,*+th,*+dh,*+hh }
QS "R_UnStrident" { *+p,*+pd,*+b,*+m,*+t,*+td,*+d,*+dd,*+n,*+en,*+k,*+kd,*+g,*+ng,*+l,*+el,*+r,*+y,*+w }
QS "R_Glide" { *+hh,*+l,*+el,*+r,*+y,*+w }
QS "R_Syllabic" { *+en,*+m,*+l,*+el,*+er }
QS "R_Unvoiced-Cons" { *+p,*+pd,*+t,*+td,*+k,*+kd,*+s,*+sh,*+f,*+th,*+hh,*+ch }
QS "R_Voiced-Cons" { *+jh,*+b,*+d,*+dd,*+dh,*+g,*+y,*+l,*+el,*+m,*+n,*+en,*+ng,*+r,*+v,*+w,*+z }
QS "R_Unvoiced-All" { *+p,*+pd,*+t,*+td,*+k,*+kd,*+s,*+sh,*+f,*+th,*+hh,*+ch,*+sil }
QS "R_Long" { *+iy,*+aa,*+ow,*+ao,*+uw,*+en,*+m,*+l,*+el }
QS "R_Short" { *+eh,*+ey,*+aa,*+ih,*+ay,*+oy,*+ah,*+ax,*+uh }
QS "R_Dipthong" { *+ey,*+ay,*+oy,*+aa,*+er,*+en,*+m,*+l,*+el }
QS "R_Front-Start" { *+ey,*+aa,*+er }
QS "R_Fronting" { *+ay,*+ey,*+oy }
QS "R_High" { *+ih,*+uw,*+aa,*+ax,*+iy }
QS "R_Medium" { *+ey,*+er,*+aa,*+ax,*+eh,*+en,*+m,*+l,*+el }
QS "R_Low" { *+eh,*+ay,*+aa,*+aw,*+ao,*+oy }
QS "R_Rounded" { *+ao,*+uw,*+aa,*+ax,*+oy,*+w }
QS "R_Unrounded" { *+eh,*+ih,*+aa,*+er,*+ay,*+ey,*+iy,*+aw,*+ah,*+ax,*+en,*+m,*+hh,*+l,*+el,*+r,*+y }
QS "R_NonAffricate" { *+s,*+sh,*+z,*+f,*+v,*+th,*+dh }
QS "R_Affricate" { *+ch,*+jh }
QS "R_IVowel" { *+ih,*+iy }
QS "R_EVowel" { *+eh,*+ey }
QS "R_AVowel" { *+eh,*+aa,*+er,*+ay,*+aw }
QS "R_OVowel" { *+ao,*+oy,*+aa }
QS "R_UVowel" { *+aa,*+ax,*+en,*+m,*+l,*+el,*+uw }
QS "R_Voiced-Stop" { *+b,*+d,*+dd,*+g }
QS "R_Unvoiced-Stop" { *+p,*+pd,*+t,*+td,*+k,*+kd }
QS "R_Front-Stop" { *+p,*+pd,*+b }
QS "R_Central-Stop" { *+t,*+td,*+d,*+dd }
QS "R_Back-Stop" { *+k,*+kd,*+g }
QS "R_Voiced-Fric" { *+z,*+sh,*+dh,*+ch,*+v }
QS "R_Unvoiced-Fric" { *+s,*+sh,*+th,*+f,*+ch }
QS "R_Front-Fric" { *+f,*+v }
QS "R_Central-Fric" { *+s,*+z,*+th,*+dh }
QS "R_Back-Fric" { *+sh,*+ch,*+jh }
QS "R_aa" { *+aa }
QS "R_ae" { *+ae }
QS "R_ah" { *+ah }
QS "R_ao" { *+ao }
QS "R_aw" { *+aw }
QS "R_ax" { *+ax }
QS "R_ay" { *+ay }
QS "R_b" { *+b }
QS "R_ch" { *+ch }
QS "R_d" { *+d }
QS "R_dd" { *+dd }
QS "R_dh" { *+dh }
QS "R_dx" { *+dx }
QS "R_eh" { *+eh }
QS "R_el" { *+el }
QS "R_en" { *+en }
QS "R_er" { *+er }
QS "R_ey" { *+ey }
QS "R_f" { *+f }
QS "R_g" { *+g }
QS "R_hh" { *+hh }
QS "R_ih" { *+ih }
QS "R_iy" { *+iy }
QS "R_jh" { *+jh }
QS "R_k" { *+k }
QS "R_kd" { *+kd }
QS "R_l" { *+l }
QS "R_m" { *+m }
QS "R_n" { *+n }
QS "R_ng" { *+ng }
QS "R_ow" { *+ow }
QS "R_oy" { *+oy }
QS "R_p" { *+p }
QS "R_pd" { *+pd }
QS "R_r" { *+r }
QS "R_s" { *+s }
QS "R_sh" { *+sh }
QS "R_t" { *+t }
QS "R_td" { *+td }
QS "R_th" { *+th }
QS "R_ts" { *+ts }
QS "R_uh" { *+uh }
QS "R_uw" { *+uw }
QS "R_v" { *+v }
QS "R_w" { *+w }
QS "R_y" { *+y }
QS "R_z" { *+z }
QS "L_NonBoundary" { *-* }
QS "L_Silence" { sil-* }
QS "L_Stop" { p-*,pd-*,b-*,t-*,td-*,d-*,dd-*,k-*,kd-*,g-* }
QS "L_Nasal" { m-*,n-*,en-*,ng-* }
QS "L_Fricative" { s-*,sh-*,z-*,f-*,v-*,ch-*,jh-*,th-*,dh-* }
QS "L_Liquid" { l-*,el-*,r-*,w-*,y-*,hh-* }
QS "L_Vowel" { eh-*,ih-*,ao-*,aa-*,uw-*,ah-*,ax-*,er-*,ay-*,oy-*,ey-*,iy-*,ow-* }
QS "L_C-Front" { p-*,pd-*,b-*,m-*,f-*,v-*,w-* }
QS "L_C-Central" { t-*,td-*,d-*,dd-*,en-*,n-*,s-*,z-*,sh-*,th-*,dh-*,l-*,el-*,r-* }
QS "L_C-Back" { sh-*,ch-*,jh-*,y-*,k-*,kd-*,g-*,ng-*,hh-* }
QS "L_V-Front" { iy-*,ih-*,eh-* }
QS "L_V-Central" { eh-*,aa-*,er-*,ao-* }
QS "L_V-Back" { uw-*,aa-*,ax-*,uh-* }
QS "L_Front" { p-*,pd-*,b-*,m-*,f-*,v-*,w-*,iy-*,ih-*,eh-* }
QS "L_Central" { t-*,td-*,d-*,dd-*,en-*,n-*,s-*,z-*,sh-*,th-*,dh-*,l-*,el-*,r-*,eh-*,aa-*,er-*,ao-* }
QS "L_Back" { sh-*,ch-*,jh-*,y-*,k-*,kd-*,g-*,ng-*,hh-*,aa-*,uw-*,ax-*,uh-* }
QS "L_Fortis" { p-*,pd-*,t-*,td-*,k-*,kd-*,f-*,th-*,s-*,sh-*,ch-* }
QS "L_Lenis" { b-*,d-*,dd-*,g-*,v-*,dh-*,z-*,sh-*,jh-* }
QS "L_UnFortLenis" { m-*,n-*,en-*,ng-*,hh-*,l-*,el-*,r-*,y-*,w-* }
QS "L_Coronal" { t-*,td-*,d-*,dd-*,n-*,en-*,th-*,dh-*,s-*,z-*,sh-*,ch-*,jh-*,l-*,el-*,r-* }
QS "L_NonCoronal" { p-*,pd-*,b-*,m-*,k-*,kd-*,g-*,ng-*,f-*,v-*,hh-*,y-*,w-* }
QS "L_Anterior" { p-*,pd-*,b-*,m-*,t-*,td-*,d-*,dd-*,n-*,en-*,f-*,v-*,th-*,dh-*,s-*,z-*,l-*,el-*,w-* }
QS "L_NonAnterior" { k-*,kd-*,g-*,ng-*,sh-*,hh-*,ch-*,jh-*,r-*,y-* }
QS "L_Continuent" { m-*,n-*,en-*,ng-*,f-*,v-*,th-*,dh-*,s-*,z-*,sh-*,hh-*,l-*,el-*,r-*,y-*,w-* }
QS "L_NonContinuent" { p-*,pd-*,b-*,t-*,td-*,d-*,dd-*,k-*,kd-*,g-*,ch-*,jh-* }
QS "L_Strident" { s-*,z-*,sh-*,ch-*,jh-* }
QS "L_NonStrident" { f-*,v-*,th-*,dh-*,hh-* }
QS "L_UnStrident" { p-*,pd-*,b-*,m-*,t-*,td-*,d-*,dd-*,n-*,en-*,k-*,kd-*,g-*,ng-*,l-*,el-*,r-*,y-*,w-* }
QS "L_Glide" { hh-*,l-*,el-*,r-*,y-*,w-* }
QS "L_Syllabic" { en-*,m-*,l-*,el-*,er-* }
QS "L_Unvoiced-Cons" { p-*,pd-*,t-*,td-*,k-*,kd-*,s-*,sh-*,f-*,th-*,hh-*,ch-* }
QS "L_Voiced-Cons" { jh-*,b-*,d-*,dd-*,dh-*,g-*,y-*,l-*,el-*,m-*,n-*,en-*,ng-*,r-*,v-*,w-*,z-* }
QS "L_Unvoiced-All" { p-*,pd-*,t-*,td-*,k-*,kd-*,s-*,sh-*,f-*,th-*,hh-*,ch-*,sil-* }
QS "L_Long" { iy-*,aa-*,ow-*,ao-*,uw-*,en-*,m-*,l-*,el-* }
QS "L_Short" { eh-*,ey-*,aa-*,ih-*,ay-*,oy-*,ah-*,ax-*,uh-* }
QS "L_Dipthong" { ey-*,ay-*,oy-*,aa-*,er-*,en-*,m-*,l-*,el-* }
QS "L_Front-Start" { ey-*,aa-*,er-* }
QS "L_Fronting" { ay-*,ey-*,oy-* }
QS "L_High" { ih-*,uw-*,aa-*,ax-*,iy-* }
QS "L_Medium" { ey-*,er-*,aa-*,ax-*,eh-*,en-*,m-*,l-*,el-* }
QS "L_Low" { eh-*,ay-*,aa-*,aw-*,ao-*,oy-* }
QS "L_Rounded" { ao-*,uw-*,aa-*,ax-*,oy-*,w-* }
QS "L_Unrounded" { eh-*,ih-*,aa-*,er-*,ay-*,ey-*,iy-*,aw-*,ah-*,ax-*,en-*,m-*,hh-*,l-*,el-*,r-*,y-* }
QS "L_NonAffricate" { s-*,sh-*,z-*,f-*,v-*,th-*,dh-* }
QS "L_Affricate" { ch-*,jh-* }
QS "L_IVowel" { ih-*,iy-* }
QS "L_EVowel" { eh-*,ey-* }
QS "L_AVowel" { eh-*,aa-*,er-*,ay-*,aw-* }
QS "L_OVowel" { ao-*,oy-*,aa-* }
QS "L_UVowel" { aa-*,ax-*,en-*,m-*,l-*,el-*,uw-* }
QS "L_Voiced-Stop" { b-*,d-*,dd-*,g-* }
QS "L_Unvoiced-Stop" { p-*,pd-*,t-*,td-*,k-*,kd-* }
QS "L_Front-Stop" { p-*,pd-*,b-* }
QS "L_Central-Stop" { t-*,td-*,d-*,dd-* }
QS "L_Back-Stop" { k-*,kd-*,g-* }
QS "L_Voiced-Fric" { z-*,sh-*,dh-*,ch-*,v-* }
QS "L_Unvoiced-Fric" { s-*,sh-*,th-*,f-*,ch-* }
QS "L_Front-Fric" { f-*,v-* }
QS "L_Central-Fric" { s-*,z-*,th-*,dh-* }
QS "L_Back-Fric" { sh-*,ch-*,jh-* }
QS "L_aa" { aa-* }
QS "L_ae" { ae-* }
QS "L_ah" { ah-* }
QS "L_ao" { ao-* }
QS "L_aw" { aw-* }
QS "L_ax" { ax-* }
QS "L_ay" { ay-* }
QS "L_b" { b-* }
QS "L_ch" { ch-* }
QS "L_d" { d-* }
QS "L_dd" { dd-* }
QS "L_dh" { dh-* }
QS "L_dx" { dx-* }
QS "L_eh" { eh-* }
QS "L_el" { el-* }
QS "L_en" { en-* }
QS "L_er" { er-* }
QS "L_ey" { ey-* }
QS "L_f" { f-* }
QS "L_g" { g-* }
QS "L_hh" { hh-* }
QS "L_ih" { ih-* }
QS "L_iy" { iy-* }
QS "L_jh" { jh-* }
QS "L_k" { k-* }
QS "L_kd" { kd-* }
QS "L_l" { l-* }
QS "L_m" { m-* }
QS "L_n" { n-* }
QS "L_ng" { ng-* }
QS "L_ow" { ow-* }
QS "L_oy" { oy-* }
QS "L_p" { p-* }
QS "L_pd" { pd-* }
QS "L_r" { r-* }
QS "L_s" { s-* }
QS "L_sh" { sh-* }
QS "L_t" { t-* }
QS "L_td" { td-* }
QS "L_th" { th-* }
QS "L_ts" { ts-* }
QS "L_uh" { uh-* }
QS "L_uw" { uw-* }
QS "L_v" { v-* }
QS "L_w" { w-* }
QS "L_y" { y-* }
QS "L_z" { z-* }
TR 2"
Dopo aver copiato quello di sopra, ricordatevi di lasciare un rigo vuoto alla fine di tree.hed (cioè dopo TR 2).
Salvate il file e chiudetelo.
Scrivete sulla cygwin:
dos2unix tree.hed (invio)
perl ../HTK_scripts/mkclscript.prl TB 350 monophones0 >> tree.hed (invio)
Non chiudete la cygwin.
Aprite nuovamente il file tree.hed e posizionate il cursore del mouse alla fine del file (cioè dopo l'ultimo carattere che vedete) e premete invio due volte (lasciando 2 righe vuote).
Aggiungete, continuando a scrivere (questa volta scrivendo i doppi apici):
TR 1
AU "fulllist"
CO "tiedlist"
ST "trees"
Non c'è bisogno del rigo vuoto alla fine. Salvate il file tree.hed e chiudetelo.
Create altre 3 cartelle dentro a manual:
-hmm13
-hmm14
-hmm15
Scrivete sopra la cygwin:
dos2unix tree.hed (invio)
HHEd -A -D -T 1 -H hmm12/macros -H hmm12/hmmdefs -M hmm13 tree.hed triphones1 (invio)
HERest -A -D -T 1 -T 1 -C config -I wintri.mlf -s stats -t 250.0 150.0 3000.0 -S train.scp -H hmm13/macros -H hmm13/hmmdefs -M hmm14 tiedlist (invio)
HERest -A -D -T 1 -T 1 -C config -I wintri.mlf -s stats -t 250.0 150.0 3000.0 -S train.scp -H hmm14/macros -H hmm14/hmmdefs -M hmm15 tiedlist (invio)
Questo creerà i seguenti file:
- in manual: tiedlist;
- in hmm13: hmmdefs e macros;
- in hmm14: hmmdefs e macros;
- in hmm15: hmmdefs e macros.
Abbiamo finito!
Avete appena concluso lo step 10 del tutorialvoxforge, che trovate qui: www.voxforge.org/home/dev/acousticmodels/windows/create/htkjulius/tutorial/triphones...
Nel prossimo post eseguiremo Julius, nella sua versione 4.2.1. |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 21/06/2013 16:02 | |
Esecuzione di Julius.
Abbiamo tutto quello che serve a Julius, non ci resta che fare poche semplici operazioni per mandarlo in esecuzione.
Due cose da fare..
La prima.
Aprite risorse del computer, poi cygwin, poi home, poi nomeUtente, poi voxforge, poi manual.
Dentro la cartella manual create un nuovo file, chiamatelo julius.jconf.
Dentro al file julius.jconf, scrivete quel che segue tra doppi apici (senza copiare i doppi apici):
"-dfa sample.dfa
-v sample.dict
-h hmm15/hmmdefs
-hlist tiedlist
-smpFreq 48000"
Salvate il file julius.jconf e chiudetelo.
Aprite la cygwin e scrivete:
cd voxforge (invio)
cd manual (invio)
dos2unix julius.jconf (invio)
Chiudete la cygwin.
La seconda.
La versione di Julius che abbiamo scaricato NON è idonea per funzionare su sistemi moderni (da windows XP in poi), tuttavia è l'unica che ci permetteva di creare quel che ci serviva in maniera conforme al tutorial voxforge.
Per poter eseguire Julius, dobbiamo scaricare una diversa distribuzione. Per questo tutorial, useremo la versione 4.2.1.
Cliccate sul seguente link e scaricate Julius4.2:
http://sourceforge.jp/projects/julius/downloads/54278/julius-4.2.1-win32bin.zip/
Copiate il file appena scaricato.
Aprite risorse del computer, poi cygwin.
Rinominate la cartella "Julius", chiamandola JuliusInstallabile.
Incollate dentro la cartella cygwin, il file che avete scaricato.
Selezionate il file appena scaricato e scompattatelo all'interno della cartella cygwin.
Al termine dell'operazione di estrazione, cancellate il file .zip.
Rinominate la nuova cartella che vi trovate e chiamatela "Julius".
Vi consiglio di non cancellare la cartella JuliusInstallabile, potrebbe servirvi in futuro per ricreare modelli acustici seguendo questo tutorial. Infatti, vi basterà invertire i nomi delle cartelle Julius e JuliusInstallabile, per poter utilizzare nuovamente questo tutorial..
Mandiamo in esecuzione Julius.
Attaccate un microfono al computer e spegnete le casse.
Scrivete sulla cygwin:
cd voxforge (invio)
cd manual (invio)
julius-4.2.1 -input mic -C julius.jconf (invio)
Buon divertimento! [Modificato da calel82 24/06/2013 12:55] |
| |
| | | OFFLINE | | Post: 2 | Città: JESOLO | Età: 38 | Sesso: Maschile | |
|
| 25/10/2013 12:28 | |
Ciao...
e solo un'idea, ma vorrei sapere se è fattibile:
- premetto che userei la traduzione dei fonemi in inglese (esempio: casa => k ae s ae)
- faccio apprendere solo i fonemi che mi interessano e che non esistono in inglese (esempio: gn)
- gli faccio fare tutto il procedimento fino a completare lo step 9
- inserisco solo i fonemi che mi interessano nell'elenco fonetico inglese
- procedo dallo step 9 con questo modello
In questo modo basterebbe solo "insegnare" pochi fonemi e risparmiare tempo, giusto? |
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 25/10/2013 13:38 | |
Ciao frenzisys,
è fattibile, solo non capisco cosa vuoi fare nello step 9...
Il modello fonetico lo puoi sviluppare come vuoi nel .voca..
Basta che poi utilizzi sempre lo stesso per tutto il procedimento!
Nello step 9, il modello fonetico già è stato elaborato almeno 3 volte.
Fammi sapere se hai difficoltà.
Buona giornata C. |
| |
| | | OFFLINE | | Post: 2 | Città: JESOLO | Età: 38 | Sesso: Maschile | |
|
| 25/10/2013 14:25 | |
per creare le combinazioni dei fonemi avendo però fatto un training solo su quelli che in inglese non ci sono.
per esempio il 'gn' in inglese non esiste, ma ci si avvicina il suono canyon (k ae n y ax n) e la r inglese non vibra.
in pratica farei solo dei file audio e delle codifiche solo su questi due suoni (il lavoro diminuirebbe di moltissimo) e li inserirei nei file hmmdefs. da ciò creerei solo le combinazioni dei fonemi partendo dal passo 9...
non penso che mi darebbero problemi i passi successivi...
|
| |
| | | OFFLINE | Post: 26 | Sesso: Maschile | |
|
| 28/10/2013 17:19 | |
Non credo che tutto andrà liscio!
Ricordati che stai costruendo un modello fonetico speaker-dipendent..
Non puoi mettere mano tu agli hmmdefs.. Se li modifichi in maniera non opportuna, rischi di creare un modello acustico che non riconosce niente, oppure non leggibile da Julius, oppure -addirittura- che la prossima esecuzione di Herest ti dia "FATAL ERROR"!
La cosa migliore sarebbe, almeno x la mia esperienza a riguardo:
1- Scegli il dominio di parole da utilizzare;
2- Costruisci la fonetica utilizzando i fonemi che vuoi;
3- Segui tutti i passi standard illustrati qui o su voxforge.
Tieni presente che Herest (che crea gli hmmdefs) non considera un solo fonema (una coppia di fonemi o 3 fonemi, dipende da come la utilizzi) alla volta, ma ha un funzionamento molto più complesso...
Es del funzionamento di Herest per singoli fonemi:
parte dal primo fonema della prima parola del primo sample e ne costruisce un modello nascosto di markov con accuratezza 1.
Elabora il secondo fonema della prima parola del primo sample, controlla se è uguale agli altri fonemi fin ora incontrati e se trova uguaglianze ne updata il modello nascosto corrispondente incrementando l'accuratezza di un fattore dipendente da tutti i fonemi fin ora considerati..
Ciò significa che una modifica effettuata a mano in un file hmmdefs, deve essere fatto tenendo presente l'intero modello fonetico e l'intero training (e anche i fonemi utilizzati nell'header di albero decisionale), una cosa che è difficile da fare a mano anche solo x un dominio di 10 parole.
Quel che vuoi fare tu, se ho capito bene, è prendere un modello acustico sviluppato da voxforge x l'inglese e riallinearlo a mano x l'italiano. Si può fare, ma non come intendi farlo tu. Oppure creare da zero un modello acustico utilizzando i fonemi inglesi.
Per ri-allineare un modello acustico devi avere a disposizione tutto lo speech corpus da cui è stato creato, il prompts.txt e .dict. (trovi tutto su voxforge). Dovresti comunque effettuare un training pari al 50-60% del training di partenza, ma SOLO per le stesse parole!
Se non è questa la tua intenzione, nel tuo lavoro o nei tuoi esperimenti, tieni sempre presente che la ripetizione in un solo sample della stessa parola, apporta poche modifiche ai modelli nascosti che gestiscono i relativi fonemi.. L'inserimento di poche parole in un modello acustico già esistente è -in proporzione- molto più pesante dell'inserimento di 200-300 parole.
Altrimenti, se vuoi utilizzare fonemi inglesi per costruzione fonetica di parole italiane, non hai nessun problema.
Puoi utilizzare fonemi reali dell'italiano, dell'iglese, dell'arabo o addirittura inventarli tu. Ma non sono consentite lettere accentate.
Sia questo tutorial che quello di voxforge funziona perfettamente con qualsiasi modello fonetico, purchè sia coerente. Coerente significa che per un dato suono, utilizzi sempre lo stesso fonema XD
Non so se sono stato chiaro.. |
| |
|
|
|
|